

自旋锁
如果认真看了我博客上上一篇文章,那么自旋锁就非常简单。
等于说,就是一个用 TestAndSet 方法,对 lock 的 flag 的操作进行一个自旋的等待,代码都是一模一样的。
只不过,现在是用xchg.c的汇编来做了TestAndSet()。
#include "xchg.c"
#include "spin.h"
void spinlock_init(spinlock_t *lock) {
lock->flag = 0;
}
//自旋锁初始化函数
void spinlock_acquire(spinlock_t *lock) {
while (xchg(&lock->flag, 1) == 1)
;//进行自旋
}
//自旋锁申请函数
void spinlock_release(spinlock_t *lock) {
lock->flag = 0;
}
//自旋锁释放函数
编译通过。
互斥信号量
如果认真看了我博客上上一篇文章,那么就非常简单。
首先看数据结构的定义和初始化。
typedef struct __mutex_t {
int flag;
} mutex_t;
//互斥锁结构体
void mutex_init(mutex_t *lock) {
lock->flag = 0;
}
//自旋锁初始化函数
然而问题的关键从来都是上锁和释放锁。
sys_futex()的调用我不仔细说了,主要用到的动作是FUTEX_WAIT和FUTEX_WAKE。
类比睡眠队列的代码。
void lock(loct_t* m) {
while (TestAndSet(&m->guard, 1) == 1)
; // acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park();
}
}
void unlock(){
while (TestAndSet(&m->guard, 1) == 1)
; // acquired guard lock by spinning
if (queue_empty(m->q))
m->flag = 0; // let go of lock; no one wants it
else
unpark(queue_remove(m->q)); // hold lock (for next thread!)
m->guard = 0;
}
可以简单地认为,sys_futex()完成了让线程睡觉,以及,叫线程起床,这两个步骤。
由此,上面代码中的叫线程起床的部分:
if (queue_empty(m->q))
m->flag = 0; // let go of lock; no one wants it
else
unpark(queue_remove(m->q)); // hold lock (for next thread!)
m->guard = 0;
就可以用futex来实现。
sys_futex(&lock->flag, FUTEX_WAKE, 1, NULL, NULL, 0);
那么,释放锁的部分代码就是:
void mutex_release(mutex_t *lock) {//自旋锁释放
xchg(&lock->flag, 0);
sys_futex(&lock->flag, FUTEX_WAKE, 1, NULL, NULL, 0);
}
类似的,上锁部分的代码是:
void mutex_acquire(mutex_t *lock) {//自旋锁申请
if (xchg(&lock->flag, 1) == 0) {
return;
} else {
sys_futex(&lock->flag, FUTEX_WAIT, 1, NULL, NULL ,0);
mutex_acquire(lock);
}
}
这里的意思是,如果我上锁成功(xchg(&lock->flag, 1) == 0),那么我就成功了,问题解决。
如果锁被持有了,那么,我就要让他睡觉。
sys_futex(&lock->flag, FUTEX_WAIT, 1, NULL, NULL ,0);
由于睡醒之后是在睡着的地方继续的,所以,睡醒以后,应该继续尝试获得锁。
sys_futex(&lock->flag, FUTEX_WAIT, 1, NULL, NULL ,0); mutex_acquire(lock);
编译通过。
线程安全的计数器
如果你仔细读了我之前的那篇文章,其实早就在那篇文章里面给出了完整的实现。
对于最简单的计数器,我们可以简单地写成:
void counter_init(counter_t *c, int val) {
c->val = val;
lock_init((void*) &c->lock);
}
int counter_get_value(counter_t *c) {
lock_acquire((void*) &c->lock);
int val = c->val;
lock_release((void*) &c->lock);
return val;
}
void counter_increment(counter_t *c) {
lock_acquire((void*) &c->lock);
c->val++;
lock_release((void*) &c->lock);
}
void counter_decrement(counter_t *c) {
lock_acquire((void*) &c->lock);
c->val--;
lock_release((void*) &c->lock);
}
如你所见,计数器加就是val++,减就是val--,初始化就是赋初值,获得计数值就是返回计数器的值。
所谓的线程安全,只要简单对临界操作加锁就可以了。
由于锁有不同的实现,所以这里用了lock_acquire()和lock_release()的接口的形式,这样就不需要关心到底是spin_acquire()还是mutex_acquire()或者pthread_mutex_acquire()了。
不过,当然也可以写成多线程性能最好的那种写法,就是分局部计数器和全局计数器的那种方法,那段代码在我前面那篇文章也早已经给出了。
对于counter_init(),几乎不需要修改,如果想要保持函数原型一致,那就把阈值写成一个常量。
对于counter_get_value(),注意,显然这里需要的是一个精确值,所以,不可能返回全局计数器的值,必须先将所有线程的局部计数器的值与全局计数器的值做同步,然后再返回。同样地,这段代码我在之前的文章中也已经优化过了,返回的就是精确值了。
int getAcuracy(counter_t* c) {
for (int i = 0; i < NUMCPUS; i++){
pthread_mutex_lock(&c->llock[i]);
pthread_mutex_lock(&c->glock);
c->global += c->local[i];
pthread_mutex_unlock(&c->glock);
c->local[i] = 0;
pthread_mutex_unlock(&c->llock[i]);
}
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val;
}
对于计数器加和减,我为了消除代码复制,没有写两份,而是保持了update()不动,只是通过amt=1或者amt=-1来区别加减。
void counter_increment(counter_t *c) {
update(c, threadID, 1);
++threadID;
}
void counter_decrement(counter_t *c) {
update(c, threadID, -1);
++threadID;
}
特别需要指出的是,由于可能存在计数器减的情况,并且我们假设,计数器可以减到 0 以下。
如果计数器不能减到 0 以下,那么,就需要做特别的处理,例如,当计数器为 0 时发生减法,抛出异常,或者,忽视指令保持计数器值为 0……
我认为,比较合理的做法是,认为加减都是合法的,也就是,运行计数器能够进行负值的计数,毕竟谁也不知道说不定什么时候就有这个需求呢……如果业务逻辑不需要负值,那么,就应该由更上层的代码去处理负值的异常。
既然计数器有负值了,那么,对于阈值的处理,就需要分正负了,也就是,判断是不是在绝对值区间内。
if (c->local[cpu] >= c->threshold || c->local[cpu] <= -c->threshold)
由此,这段代码可以写成:
#include "lock.h"
typedef struct __counter_t {
int global;
int local[THREAD_NUM];
int threshold;
#if LOCK_TYPE == SPIN_LOCK
spinlock_t glock,llock[THREAD_NUM];
#elif LOCK_TYPE == MUTEX_LOCK
mutex_t glock,llock[THREAD_NUM];
#else
pthread_mutex_t glock,llock[THREAD_NUM];
#endif//不同的lock_type对应不同的内容
} counter_t;
int DEFAULT_THRESHOLD = 1024;
int threadID = 0;
void counter_init(counter_t *c, int value);
//计数器初始化函数
int counter_get_value(counter_t *c);
//获得计数器的当前值
void counter_increment(counter_t *c);
//计数增加
void counter_decrement(counter_t *c);
//技术减少
void update(counter_t* c, int threadID, int amt);
//更新计数器
void counter_init(counter_t* c, int value)
{//计数器初始化函数
c->threshold = DEFAULT_THRESHOLD;
c->global = value;
lock_init((void*)&c->glock);
int i;
for (i = 0; i < THREAD_NUM; i++){
c->local[i] = 0;
lock_init((void*)&c->llock[i]);
}//初始化申请的锁
//注意调用的是lock提供的接口函数而不是直接调用锁的函数
}
int counter_get_value(counter_t* c)
{//获得计数器的值
int i;
for (i = 0; i < THREAD_NUM; i++){
lock_acquire((void*)&c->llock[i]);
lock_acquire((void*)&c->glock);
c->global += c->local[i];
lock_release((void*)&c->glock);
c->local[i] = 0;
lock_release((void*)&c->llock[i]);
}
lock_acquire((void*)&c->glock);
int val = c->global;
lock_release((void*)&c->glock);
return val;
}
void update(counter_t* c, int threadID, int amt)
{//计数器更新函数
int cpu = threadID % THREAD_NUM;
lock_acquire((void*)&c->llock[cpu]);
c->local[cpu] += amt;
if (c->local[cpu] >= c->threshold || c->local[cpu] <= -(c->threshold)) {
lock_acquire((void*)&c->glock);
c->global += c->local[cpu];
lock_release((void*)&c->glock);
c->local[cpu] = 0;
}
lock_release((void*)&c->llock[cpu]);
}
void counter_increment(counter_t *c)
{//计数器加
update(c, threadID, 1);
++threadID;
}
void counter_decrement(counter_t *c)
{//计数器减
update(c, threadID, -1);
++threadID;
}
线程安全的链表
之前那篇文章已经全部实现了。
除了删除,另外实际测试中由于数据比较大,因此还要再加上free函数,这里的free只是链表的free,一些问题后续在Hash中详述。
那么类似地实现删除也是非常简单。
需要注意的是,这里的查找是要返回一个指针,而不是值,所以需要修改返回int为void*。
删除掉结点的时候记得free()。
#include "lock.c"
void list_init(list_t* L)
{//链表初始化函数
L->head = NULL;
lock_init((void*)&L->lock);
}
void list_insert(list_t *L, unsigned int key)
{//链表插入函数
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
return;
}//异常处理
new->key = key;
lock_acquire((void*)&L->lock);
new->next = L->head;
L->head = new;
lock_release((void*)&L->lock);
}
void* list_lookup(list_t *L, unsigned int key)
{//链表结点查询函数
void* rv = NULL;
lock_acquire((void*)&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
rv = curr;
break;
}
curr = curr->next;
}
lock_release((void*)&L->lock);
return rv;
}
void list_delete(list_t *L, unsigned int key)
{//链表结点删除函数
if (L->head == NULL)
return;
lock_acquire((void*)&L->lock);
node_t *index = L->head, *pre = NULL;
while (index != NULL) {
if (index->key == key) {
break;
}
pre = index;
index = index->next;
}
if (index != NULL) {
if (pre == NULL) {
L->head = L->head->next;
free(index);
}
else {
pre->next = index->next;
free(index);
}
}
lock_release((void*)&L->lock);
}
void list_free(list_t *L)
{//链表释放函数
if(L!=NULL)
{
node_t *tmp1,*tmp2;
tmp1=L->head;
while(tmp1!=NULL)
{//先释放node结点
tmp2=tmp1->next;
free(tmp1);
tmp1=tmp2;
}
free(L);//最后释放自己
}
}
线程安全的哈希表
教材上给出了部分的代码,但是要完整实现也一点不难,就是相当于链表的插入和删除。
Hash 函数可以用最简单的对 key 取模。
另外考虑线程安全,发现哈希表内部是用链表实现的。
对于求 Hash 、通过数组方法定位,显然是安全的,而临界操作也用了线程安全的链表。
因此不需要改了,直接用就是了。
但是比较容易出问题的是free()函数,首先给一个看起来绝对很正确的写法:
void hash_free(hash_t *H)
{
int i;
for(i=0;i<H->buckets;i++)
list_free((list_t*)&(hash->lists[i]));
free(H->lists);//释放指向list的指针的空间
free(H);//最后释放哈希表
}
看上去是没有什么问题。但是运行起来会出现system error。下面给一个类似的代码,很C能说明问题。
int *a=(int*)malloc(sizeof(int)*100);
for(i=0;i<100;i++)
free(a+i);
很显然,上面的两段代码的错误是相同的,malloc申请的空间不可以单个释放而要整个释放。但是,list结点释放的时候自身肯定也会被释放,所以Hash表的free函数在这里不能调用list的free函数,下面给出整个实现。
#define BUCKETS (101)
typedef struct __hash_t {
int buckets;
list_t* lists;
} hash_t;//包含分类元和一个指向list的指针
void hash_init(hash_t *H, int buckets)
{//哈希表初始化
H->buckets = buckets;
H->lists = (list_t*) malloc(sizeof(list_t) * buckets);
for (int i = 0; i < buckets; ++i)
list_init((list_t*)&(H->lists[i]));
}
void hash_insert(hash_t *H, int key)
{//哈希表插入函数
int bucket = key % H->buckets;
return list_insert((list_t*)&(H->lists[bucket]), key);
}
void* hash_lookup(hash_t *H, int key)
{//哈希表查询函数
int bucket = key % H->buckets;
return list_lookup((list_t*)&(H->lists[bucket]), key);
}
void hash_delete(hash_t *hash, unsigned int key)
{//哈希表删除函数
int bucket = key % hash->buckets;
list_delete((list_t*)&(hash->lists[bucket]), key);
}
void hash_free(hash_t *H)
{//哈希表释放函数
int i;
for(i=0;i<H->buckets;i++)
{//先释放每个指针对应的list
list_t *L=H->lists+i;
if(L!=NULL)
{
node_t *tmp1,*tmp2;
tmp1=L->head;
while(tmp1!=NULL)
{
tmp2=tmp1->next;
free(tmp1);
tmp1=tmp2;
}
}
}//注意不能直接调用list_free函数
free(H->lists);//释放指向list的指针的空间
free(H);//最后释放哈希表
}
二相锁
在上一篇文章中已经详细说明了。
现在我们来把它实现了。
首先明确一个操作,atomic_increment()和atomic_decrement()。
显然,需要对操作进行加锁。
如果说,mutex是整个二相锁的互斥量,那么对其中的加、减操作需要另一个锁来锁这个锁,或者说,用一个守卫来保护对锁的操作。
// atomic_increment(mutex), lock->count++;
while (xchg(&(lock->atomic),1) == 1)
;
lock->count++;
lock->atomic = 0;
// atomic_decrement(mutex), lock->count--;
while (xchg(&(lock->atomic),1) == 1)
;
lock->count--;
lock->atomic = 0;
return;
这里用的xchg来保证了原子操作,同时用atomic作为守卫保护了对临界资源count的操作。
futex_wait (mutex, v);的实现是:
sys_futex(&(lock->mutex), FUTEX_WAIT, v, 0, 0, 0);
futex_wake (mutex);的实现是:
sys_futex(&(lock->mutex), FUTEX_WAKE, lock->count, 0, 0, 0);
剩下的代码照抄上一篇文章的代码就好了。
void mutex_lock (int *mutex) {
int v;
/* Bit 31 was clear, we got the mutex (this is the fastpath) */
if (atomic_bit_test_set (mutex, 31) == 0)
return;
atomic_increment (mutex);
while (1) {
if (atomic_bit_test_set (mutex, 31) == 0) {
atomic_decrement (mutex);
return;
}
/* We have to wait now. First make sure the futex value
we are monitoring is truly negative (i.e. locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait (mutex, v);
}
}
void mutex_unlock (int *mutex) {
/* Adding 0x80000000 to the counter results in 0 if and only if
there are not other interested threads */
if (atomic_add_zero (mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex,
wake one of them up. */
futex_wake (mutex);
}
只是需要注意一个地方。
/* Adding 0x80000000 to the counter results in 0 if and only if
there are not other interested threads */
if (atomic_add_zero (mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex,
wake one of them up. */
这里的0x80000000本质上是看还有没有别的线程在等待锁,如果有,那么就唤醒其中之一。
那么,我们的实现方法就可以很简单地,用一个count了。
#include "two_phase.h"
#include "sys_futex.c"
#include "xchg.c"
typedef struct __two_phase_t {
int mutex;
int atomic;
int count;
}
void two_phase_init(two_phase_t* lock){
lock->mutex = 0;
lock->atomic = 0;
lock->count = 0;
}
void two_phase_acquire(two_phase_t* lock){
if (xchg(&(lock->mutex, 31)) == 0)
return;
// atomic_increment(mutex), lock->count++;
while (xchg(&(lock->atomic),1) == 1)
;
lock->count++;
lock->atomic = 0;
while (1) {
if (xchg(&(lock->mutex, 31)) == 0) {
// atomic_decrement(mutex), lock->count--;
while (xchg(&(lock->atomic),1) == 1)
;
lock->count--;
lock->atomic = 0;
return;
}
int v = lock->mutex;
if (v >= 0)
continue;
sys_futex(&(lock->mutex), FUTEX_WAIT, v, 0, 0, 0);
}
}
void two_phase_release(two_phase_t *lock) {
lock->mutex = 0;
if (lock->count != 0)
sys_futex(&(lock->mutex), FUTEX_WAKE, lock->count, 0, 0, 0);
}
公平性
下面我们考虑锁的公平性。
在上面一篇文章中已经分析过了,怎么保证一个锁是公平的。
typedef struct __lock_t {
int ticket;
int turn;
} lock_t;
void lock_init(lock_t* lock){
lock->ticket = 0;
lock->turn = 0;
}
void lock(lock_t* lock) {
int myturn = FetchAndAdd(&lock->ticket);
while (lock->turn != myturn)
; // spin
}
void unlock(lock_t * lock){
lock->turn = lock->turn + 1;
}
但是这样浪费了大量的CPU资源。
解决方法是一个等待队列。
这在上一篇文章见过了。
typedef struct __lock_t {
int flag;
int guard;
queue_t *q;
} lock_t;
void lock_init(lock_t* lock){
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(loct_t* m) {
while (TestAndSet(&m->guard, 1) == 1)
; // acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park();
}
}
void unlock(){
while (TestAndSet(&m->guard, 1) == 1)
; // acquired guard lock by spinning
if (queue_empty(m->q))
m->flag = 0; // let go of lock; no one wants it
else
unpark(queue_remove(m->q)); // hold lock (for next thread!)
m->guard = 0;
}
首先需要实现一个线程安全的队列。
也已经解释过了。
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
先用自旋锁实现一个线程安全的队列,用线程安全的队列实现一个公平的锁。
那么,就等于是把上面三段代码杂糅一下。
#include "xchg.c"
#include "sys_futex.c"
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
spinlock_t headLock;
spinlock_t tailLock;
int size;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
spinlock_init(&q->headLock);
spinlock_init(&q->tailLock);
q->size = 0;
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
tmp->value = value;
tmp->next = NULL;
spinlock_acquire(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
size++;
spinlock_release(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
spinlock_acquire(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
spinlock_release(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
size--;
spinlock_release(&q->headLock);
free(tmp);
return 0;
}
typedef struct __justifylock_t {
int flag;
int guard;
queue_t *q;
} justifylock_t;
void justifylock_init(lock_t* lock){
m->flag = 0;
m->guard = 0;
Queue_Init(m->q);
}
void justifylock_acquire(loct_t* m) {
while (xchg(&m->guard, 1) == 1)
; // acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
Queue_Enqueue(m->q, gettid());
m->guard = 0;
park();
}
}
void justifylock_release(loct_t* m){
while (xchg(&m->guard, 1) == 1)
; // acquired guard lock by spinning
if (q->size == 0)
m->flag = 0; // let go of lock; no one wants it
else
unpark(Queue_Dequeue(m->q)); // hold lock (for next thread!)
m->guard = 0;
}
统一接口lock
最后统一一下接口,另外定义了新的文件lock.c和lock.h,生成了动态链接库liblock.so,通过定义lock_type宏来实现通过上层函数调用不同的锁。
难点主要在于指针的强制类型转换。
#define PTHREAD_LOCK 0 #define SPIN_LOCK 1 #define MUTEX_LOCK 2 #define LOCK_TYPE 0 //标志锁的类型 void lock_init(void* lock_t); //锁初始化函数 void lock_acquire(void *lock_t); //锁申请函数 void lock_release(void *lock_t); //锁释放函数
条件变量
最简单的锁,白痴都会做。
所以要加很多东西。
刚才所做的一切其实只是保证了对临界资源的互斥访问,但是并不能达到同步的要求。
所以,下面来写条件变量。
条件变量是另外一种同步机制,用于线程的互斥,并且能够达到同步的效果。条件变量允许线程由于一些暂时没有达到的条件而阻塞。通常,等待另一个线程完成该线程所需要的条件。条件达到时,另外一个线程发送一个信号,唤醒该线程。
在linux系统中,条件变量对应的一组操作函数是是pthread_cond_wait和pthread_cond_signal。
条件变量与互斥量一起使用,一般情况是:一个线程锁住一个互斥量,然后当它不能获得它期待的结果时,等待一个条件变量;最后另外一个线程向它发送信号,使得它可以继续执行。
#define atomic_add(P, V) __sync_add_and_fetch((P), (V))
#define cmpxchg(P, O, N) __sync_val_compare_and_swap((P), (O), (N))
#define INT_MAX 2147483647
#define pthread_type 0
#define cv_type 1
#define type_value 1
static inline unsigned xchg_32(void *ptr, unsigned x)
{//将x放入寄存器中与第一个指针参数所指的内容交换,返回所指内容原先的值
__asm__ __volatile__("xchgl %0,%1"
:"=r" ((unsigned) x)
:"m" (*(volatile unsigned *)ptr), "0" (x)
:"memory");
return x;
}
//32位寄存器交换指令
typedef struct __Conditional_variables
{
mutex_t *m;
int seq;
}CV_t;
//我们设计的条件变量的数据结构
void cv_init(CV_t *c,mutex_t *m)
{
c->m=(mutex_t*)malloc(sizeof(mutex_t));
mutex_init(c->m);
c->seq=0;
}
//条件变量初始化函数
void cv_free(CV_t *c)
{
free(c->m);
free(c);
}
//条件变量释放函数
//由于空间很少,在测试的时候这部分可忽略
void cv_signal(CV_t *c)
{
atomic_add(&c->seq,1);
//唤醒一个进程
sys_futex(&c->seq,FUTEX_WAKE_PRIVATE,1,NULL,NULL,0);
}
//唤醒睡眠的单个进程
void cv_broadcast(CV_t *c)
{
mutex_t *m=c->m;
if(m->flag==0)
//判断是否有进程在等待
return;
//唤醒每一个进程
atomic_add(&c->seq,1);
sys_futex(&c->seq,FUTEX_REQUEUE_PRIVATE,1,(void *)INT_MAX,m,0);
return;
}
//广播唤醒进程
void cv_wait(CV_t *c,mutex_t *m)
{
int seq=c->seq;
if(c->m!=m)
{
//if(c->m) return ;
cmpxchg(&(c->m->flag),NULL,&(m->flag));
if(c->m!=m) return ;
}
mutex_release(m);
sys_futex(&c->seq,FUTEX_WAIT_PRIVATE,seq,NULL,NULL,0);
while(xchg_32(&(m->flag),2))
{
sys_futex(&m->flag,FUTEX_WAIT_PRIVATE,2,NULL,NULL,0);
}
return;
}
//让一个进程睡眠,直到被唤醒
另外还有两个测试函数,加和减:
pthread_t *p;
pthread_mutex_t count_lock;
pthread_cond_t count_nonzero;
unsigned count=0;
mutex_t lock;
CV_t cv;
void increment_count()
{//计数增加函数
if(type_value==pthread_type)
{//调用pthread
pthread_mutex_lock(&count_lock);
if (count == 0)
//pthread_cond_signal(&count_nonzero);
pthread_cond_broadcast(&count_nonzero);
count = count + 1;
pthread_mutex_unlock(&count_lock);
}
else
{//调用我们的条件变量
mutex_acquire(&lock);
if (count == 0)
//cv_signal(&cv);
cv_broadcast(&cv);
count = count + 1;
mutex_release(&lock);
}
}
void decrement_count()
{//计数减少函数
if(type_value==pthread_type)
{//调用pthread
pthread_mutex_lock(&count_lock);
while (count == 0)
pthread_cond_wait(&count_nonzero, &count_lock);
count = count - 1;
pthread_mutex_unlock(&count_lock);
}
else
{//调用我们的条件变量
mutex_acquire(&lock);
if (count == 0)
cv_wait(&cv,&lock);
count = count - 1;
mutex_release(&lock);
}
}
另外,测试的时候考虑极端情况,为了确保饥饿一定会发生,我们建立一半减的线程,再建立一半加的进程,这样饥饿一定会发生。
void test1(void *arg)
{//测试函数1,计数增加
int val = *(int*)arg;
while (val--)
{
increment_count();
}
}
void test2(void *arg)
{//测试函数2,计数减少
int val = *(int*)arg;
while (val--)
{
decrement_count();
}
}
for (i = 0; i < thread_no; ++i)
{//产生进程
//int ran=rand()%100+1;生成随机数
//一种思路是用随机数来引导程序进行加减法
//但问题在于不确定性很大,有可能出现死锁情况
//实际测试中,控制在一半有很大概率会发生死锁
//控制在0.51/0.49死锁概率仍然很高
if(i<=thread_no/2-1)
//说明:先让一半的进程进行减法,再让一半的进程进行加法
//这样一定会发生饥饿现象
pthread_create(p+i, NULL, (void*)test2, &number);
else
pthread_create(p+i, NULL, (void*)test1, &number);
}
for (i = 0; i < thread_no; ++i)
{
pthread_join(p[i], NULL);
//进程销毁
}
评价其性能
Counter大数据测试
首先我们进行的是counter的百万级测试,为了比较在大量数据下不同锁的性能,拉开时间差,我们进行了从1百万到一千万的一百万间隔的测试。额外说明的是,测试采用了控制变量法,保证了在测试时虚拟机的环境(内存4GB,CPU 4*1核)和相同的虚拟核心数(8),来确保测试对每个算法的公平性。
另外,由于考虑到运行时间较长,CPU不同的负载情况和温度可能会对测试效果产生较大影响,因此,测试每个案例的每组数据时,我们都会将测试时间取100次的平均值,来尽可能的减少偶发因素对实验结果的影响。
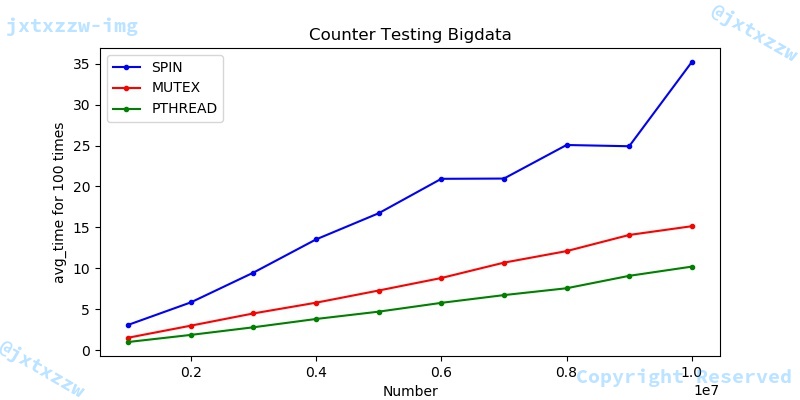
测试结果十分清晰的给出了不同锁的优劣,很显然,在性能上pthread > mutex > spin。另外需要额外补充说明的是,mutex和pthread锁关于number的时间函数具有一定的线性性,这点在后面的某些实验中会显得更加清晰。pthread的性能是毋庸置疑的,接下来,由于spin需要大量的自旋,白白浪费了CPU时间,所以spin的性能相比与mutex的互斥相差很多。
线程数性能测试
在这里,我们将核心数从1~36,在数据量1百万的情况下进行测试,测试过程中同样进行百次的平均。
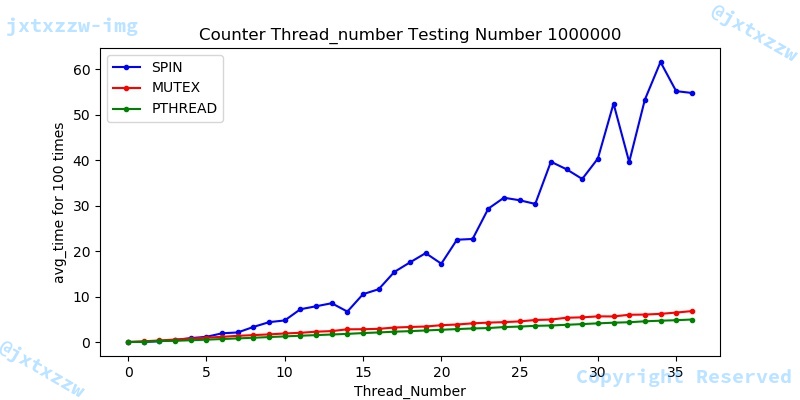
测试的情况很清晰,因为我们之前已经进行过百万乃至千万级别的counter性能测试,所以这里还关于性能差距就不再进行分析。
需要说明的第一点是,图中看起来mutex和pthread接近,实际上,由于spin的时间达到了几十秒甚至更多,使得纵坐标的单位尺度偏大。在threadnumber为36时,mutex和pthread的时间差相差一倍以上。
另一个需要说明的是,spin的时间波动很大,可能源自CPU不同的其他负载。
在这里,我们将threadnumber从1~20,number百万,来测试不同的锁在list性能效果。
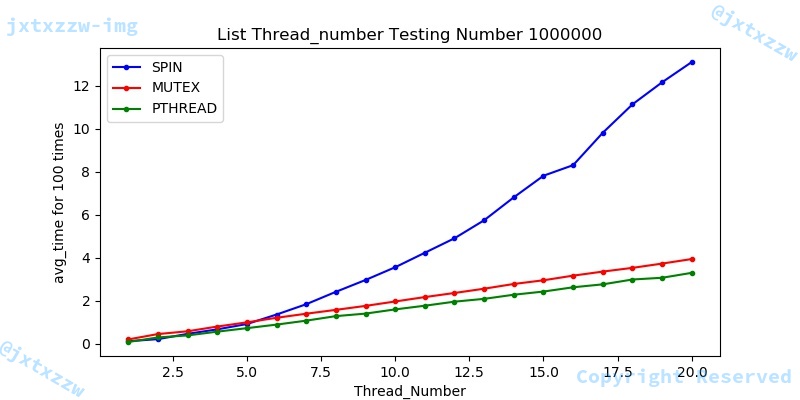
测试结果很清晰地表明,mutex和pthread的运行时间和核心数近似成一次函数关系。另外性能上,除mutex在线程数较少的情况下会略多于spin和pthread外,在线程数较多的情况下,整体性能趋势成pthread > mutex > spin。
在这里,我们将从1~36,number百万,来测试不同的锁在list性能效果。
测试结果很清晰地表明,性能上,在线程数较多的情况下,整体性能趋势成pthread > mutex > spin。
在这里,为了能够更直观的观察出在线程数较少时的性能情况,我们将横坐标用$\log_{2}{threadnumber}$表示线程数,即测试线程数1,2,4,8时的情况。
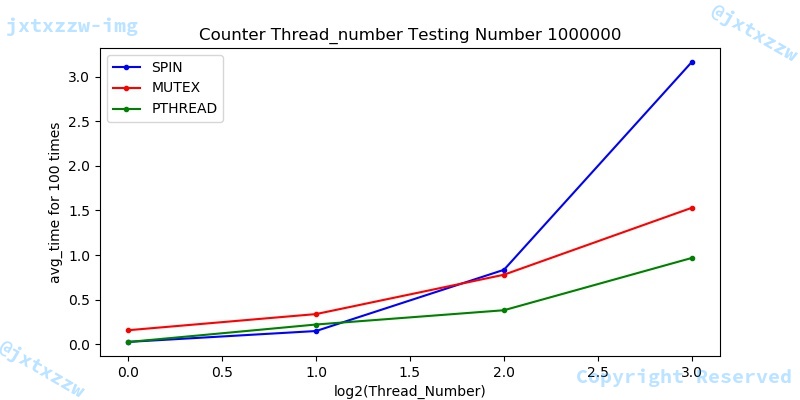
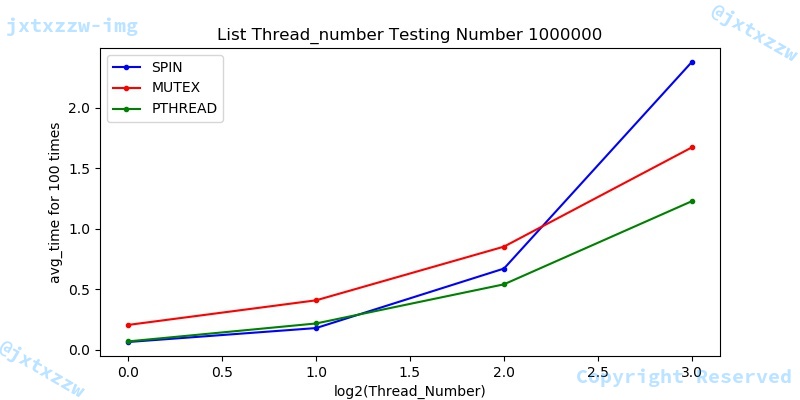
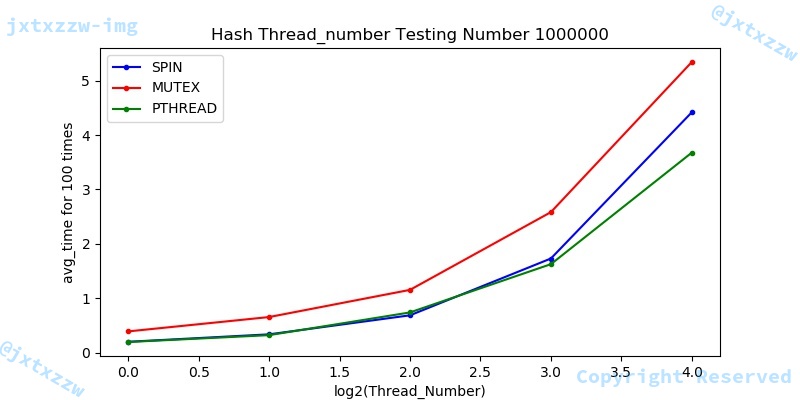
综合上述图片,可以看出,在线程数较少的时候,性能关系大致为 pthread > spin > mutex。
条件变量
由于条件变量能够及时的唤醒睡眠的线程,因此在测试的时候,特别将一半的会被饥饿的线程先产生,在产生另一半的进程,同时,控制保证所有进程刚好正常结束。数据量1000000,线程数取2-20的等差数列,公差为2。这里为了保证所有线程都能正常执行完并且时刚好执行完,所以线程数取2的倍数。
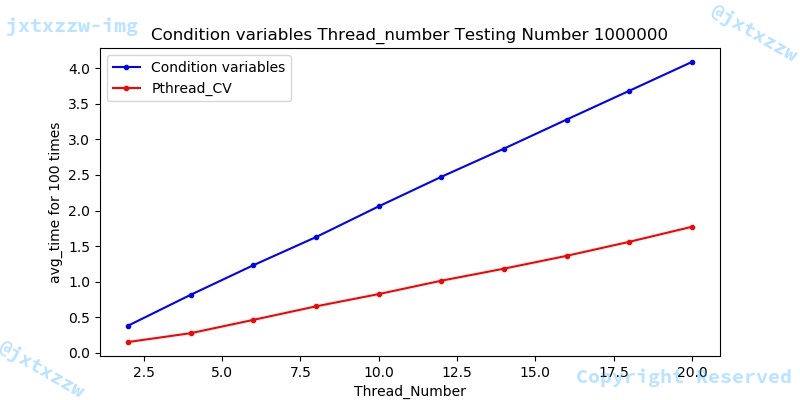
对比我们实现的condition_variavle和pthread对应的cond,可以看出cond的耗时与线程数具有良好的线性关系,由于线程数也代表了工作量(说明:每个线程的工作量是固定且独立的,总工作量与线程数目呈良好的一次关系),即可以很好地实现并发线程时的工作效率。
太强了
nbnb
tqltqltql
!
bbb
emmm
啦啦啦