

参考文献:Perform Sentiment Analysis with LSTMs Using TensorFlow
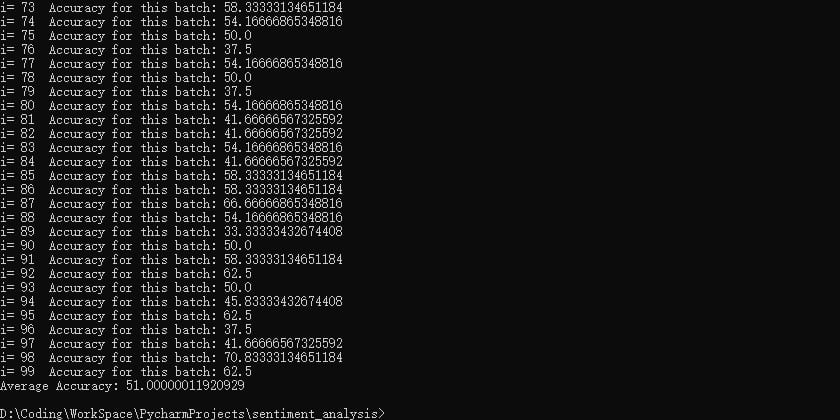
原来的代码可能哪里有点问题,准确率不应该有这么高的,修正后的准确率大概在60%,如图截图给出的是其中某次预测的准确率为51%的截图,可以看到准确率高的有70%,对于Twitter情感分析,学术顶尖的论文大概在70%的准确率。
第一件事情是把单词变成向量。
通常使用 Word2Vec 的模型。该模型采用大量句子数据集(例如英文维基百科),并为语料库中的每个不同词输出向量。模型是通过将数据集中的每个句子进行训练,具有相似上下文的单词将在向量空间中放置在相近的位置。在自然语言中,当尝试确定其含义时,单词的上下文可能非常重要。
首先,要创建词向量。为简单起见,将使用预训练好的模型。
Glove 提供了预训练的数据,矩阵包含 40 万个词向量,每个维数为 50。
数据的格式是txt,可以自己读入并处理,做好单词和向量的映射。
也可以找到 Glove 的二进制预训练数据,使用Tool to convert binary GloVe vectors to numpy array工具将二进制的文件转换成npy格式。
Glove 也提供了大量的训练样本和训练程序,网上也能找到大量的训练代码,只需要下载训练数据,然后运行官方提供的脚本,就可以完成训练。不过这一过程将耗费非常长的时间。
因为这一部分不是重点,所以我直接下载了npy格式的预训练数据集。
wordsList.npy:
下载提示
wordVectors.npy:
下载提示
先看看这一步是不是正确:
首先
import numpy as np
wordsList = np.load('wordsList.npy')
wordsList = wordsList.tolist()
wordsList = [word.decode('UTF-8') for word in wordsList]
wordVectors = np.load('wordVectors.npy')
导入数据集,然后使用wordList.index(word)得到word的索引号index,并使用wordVector[index]得到word的词向量。
运行
print(wordsList.index("hello"))
print(wordVectors[wordsList.index("hello")])
输出hello的索引号,并输出其词向量,得到索引号是 13075,词向量如下图:

对于句子的处理,可以用一个遍历来完成。
import numpy as np
wordsList = np.load('wordsList.npy')
wordsList = wordsList.tolist()
wordsList = [word.decode('UTF-8') for word in wordsList]
wordVectors = np.load('wordVectors.npy')
maxLength = 10
numDimensions = 300
s = "my name is hello world"
si = np.zeros(maxLength, dtype='int32')
s = s.strip().split()
for i in range(len(s)):
si[i] = wordsList.index(s[i])
print(si.shape)
print(si)
for i in range(len(s[i])):
print(wordVectors[si[i]])
之后要为整个训练集创建矩阵,但是每一个句子拥有多少个单词是不确定的,如何才能保证所有的记录拥有相同的维度(即,所有的句子拥有相同的长度,不足的补 0,超过的截断)却又不会丢失训练信息(即,大部分的句子仍然保留了所有的信息,而不至于被截断的部分太大)呢?
一种显而易见的做法是,令 90% 左右的句子都能够完整保留所有单词就行了。
在为整个训练集创建矩阵之前,首先花一些时间为拥有的数据类型做一下可视化,这会帮助我们确定设定最大序列长度的最佳值。
读入每个句子,然后用空格分隔,就可以统计出每个句子有多少个单词,将句子的长度添加进numWords列表,然后用matplotlib库将numWords可视化。
with open("train.txt", "r", encoding='utf-8') as f:
while True:
line=f.readline()
if not line:
break
txt = line.split("\t")[2]
counter = len(txt.split())
numWords.append(counter)
import matplotlib.pyplot as plt
plt.hist(numWords, 50)
plt.xlabel('Sequence Length')
plt.ylabel('Frequency')
plt.axis([0, 40, 0, 1000])
plt.show()
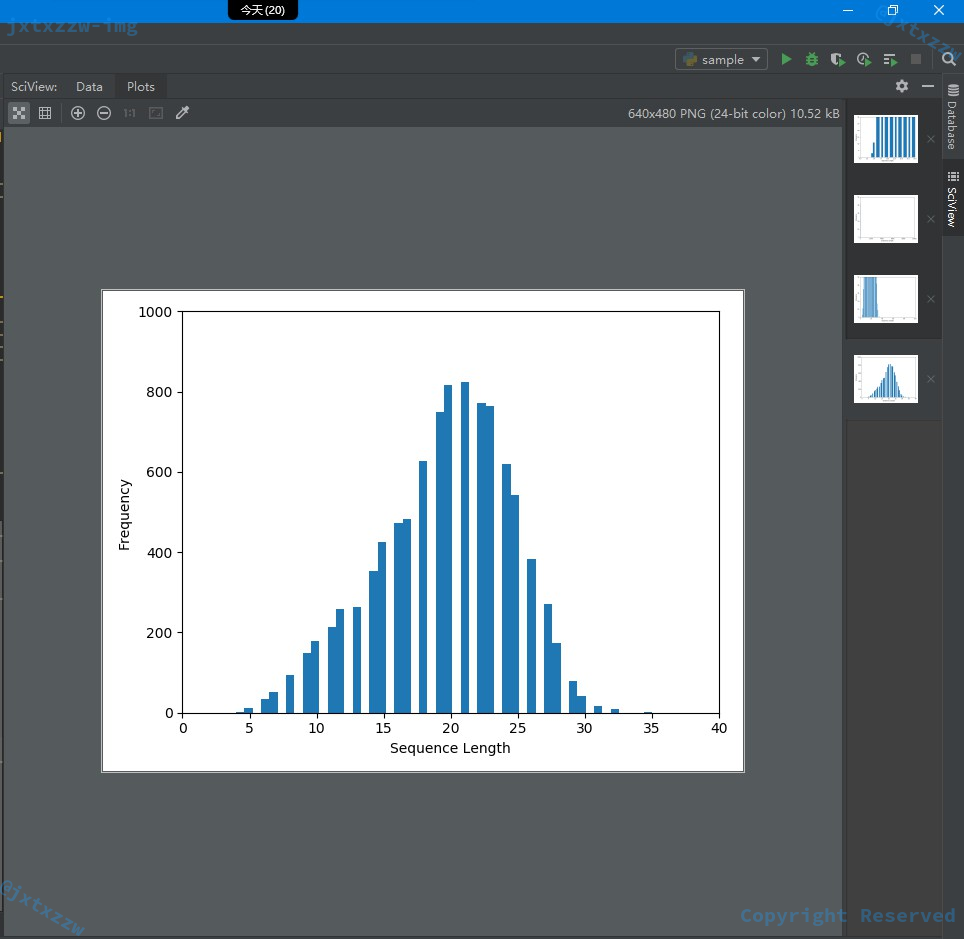
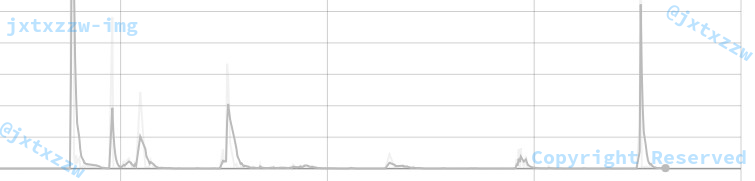
如图,可以看到,几乎所有的句子的长度都在 30 以下,那么,就可以直接令句子的最长值为 30。
这里没有取所有句子中真正最长的那个作为句子最长值,是因为这样会造成样本空间急剧增大,带来更大的运算量和更差的效率,而由于大部分都是 0,增加的运算量不能带来信息上的获益。
这样就定义了一个maxSeqLength。
maxSeqLength = 30
下面尝试将某个句子转换成 id 矩阵。
例如我随便取了训练样本中的一句话,One of my best 8th graders Kory was excited after his touchdown...,试着将这句话变成 id 矩阵,看看是什么效果。
首先用正则表达式去掉这句话中所有奇怪的数字、标点……并将所有字母换成小写。
record = "One of my best 8th graders Kory was excited after his touchdown"
tmp = np.zeros(maxSeqLength, dtype='int32')
indexCounter = 0
line = record
cleanedLine = cleanSentences(line)
split = cleanedLine.split()
for word in split:
try:
tmp[indexCounter] = wordsList.index(word)
except ValueError:
tmp[indexCounter] = UNKNOWM # Vector for unknown words
indexCounter = indexCounter + 1
print(tmp)
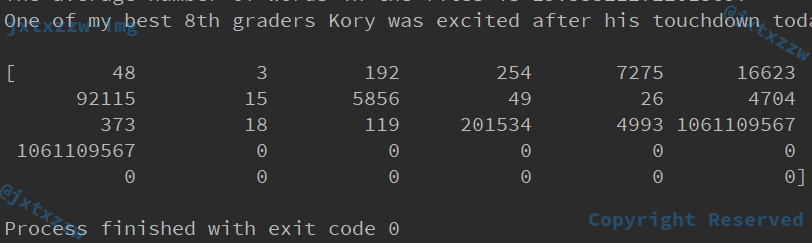
可以看到程序正常结束,并且得到了这样一个 id 矩阵。
现在,只需要对所有的句子做同样的操作。
当然,顺便要在处理每一个句子的时候,记录下它的标签是积极的,还是消极的,还是中立的。
假设已经将train.txt中所有的句子读入到内存,并且分别保存在 3 个列表中,那么下面只需分别取出每一个句子,重复上面的过程即可。
这里以处理positive sentence为例,另外两类也是类似的。
for positive_sentence in positive:
print("Processing new positive record", sentence_index)
index_counter = 0
cleaned_sentence = cleanSentences(positive_sentence)
split_sentence = cleaned_sentence.split()
for word in split_sentence:
try:
ids[sentence_index][index_counter] = wordsList.index(word)
except ValueError:
ids[sentence_index][index_counter] = UNKNOWM
index_counter = index_counter + 1
if index_counter >= maxSeqLength:
break
sentence_index = sentence_index + 1
positive是train.txt中所有的标签为positive的句子,这是一个遍历,依次处理其中的每一个句子。
为了便于观察,首先打印一句提示。
index_counter记录的是当前处理到的是这个句子的第几个单词。
然后对这个句子使用正则表达式过滤不重要的标点、数字等信息,并以空格分隔,得到split_sentence。
这样就得到了这个句子的所有单词,遍历这些单词。
如果这个单词在wordList中,则取出它的索引号,并保存在ids矩阵中,表示,第sentence_index个句子的第index_counter个单词的索引号是wordList.index(word)。
如果出现异常,说明这个单词没有出现在wordList中,那么置为UNKNOWN。
由于最大句子长度定义为maxSeqLength,所以如果超过了这么多单词,就要截断。
对于另外 2 个分类也是类似的操作。
然后把这个操作封装一下,消除代码复制。
def get_sentence_ids(sentence, ids, sentence_index):
index_counter = 0
cleaned_sentence = cleanSentences(sentence)
split_sentence = cleaned_sentence.split()
for word in split_sentence:
try:
ids[sentence_index][index_counter] = wordsList.index(word)
except ValueError:
ids[sentence_index][index_counter] = UNKNOWM
index_counter = index_counter + 1
if index_counter >= maxSeqLength:
break
def get_ids():
ids = np.zeros((numFiles, maxSeqLength), dtype='int32')
sentence_index = 0
for sentence in positive:
print("Processing new positive record", sentence_index)
get_sentence_ids(sentence, ids, sentence_index)
sentence_index = sentence_index + 1
for sentence in negative:
get_sentence_ids(sentence, ids, sentence_index)
sentence_index = sentence_index + 1
for sentence in neutral:
get_sentence_ids(sentence, ids, sentence_index)
sentence_index = sentence_index + 1
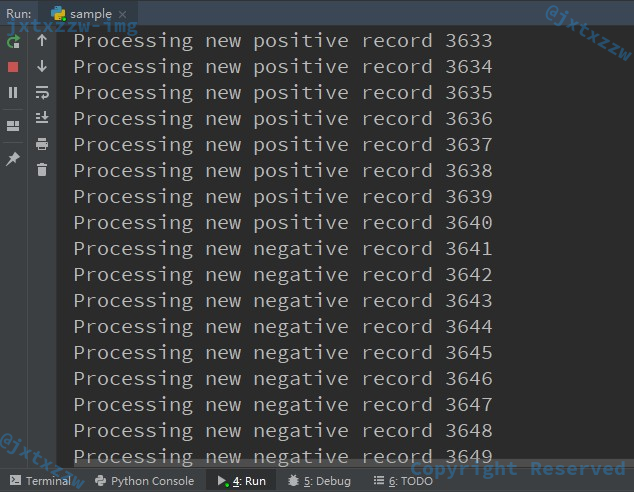
运行得到如下图:
那么,positive、negative和neutral怎么来就简单了,只需要遍历train.txt,然后取出以\t分隔的第 2 个字段的值,按照这个字段的值分别存入不同的列表即可。
numWords = []
positive = []
negative = []
neutral = []
with open("train.txt", "r", encoding='utf-8') as f:
while True:
line = f.readline()
if not line:
break
label = line.split("\t")[1]
text = line.split("\t")[2]
if label == "positive":
positive.append(text)
elif label == "negative":
negative.append(text)
else:
neutral.append(text)
counter = len(text.split())
numWords.append(counter)
验证集和测试集也是类似的处理方法,所以这里做一个封装。
def read_file(input_file):
另外考虑到,get_ids的过程非常长,如果每一次都要重新算过的话花销太大,而且事实上一旦训练集确定,得到的ids矩阵是唯一确定的,所以可以直接把处理后的结果保存下来,下次直接用。
np.save(output_file, ids)
print("Save successfully.")
至此,所有的处理部分已经结束。
strip_special_chars = re.compile("[^A-Za-z0-9 ]+")
def read_file(input_file):
positive = []
negative = []
neutral = []
with open(input_file, "r", encoding='utf-8') as f:
while True:
line = f.readline()
if not line:
break
label = line.split("\t")[1]
text = line.split("\t")[2]
if label == "positive":
positive.append(text)
elif label == "negative":
negative.append(text)
else:
neutral.append(text)
return positive, negative, neutral
def clean_sentences(string):
string = string.lower().replace("<br />", " ")
return re.sub(strip_special_chars, "", string.lower())
def get_sentence_ids(sentence, ids, sentence_index):
index_counter = 0
cleaned_sentence = clean_sentences(sentence)
split_sentence = cleaned_sentence.split()
for word in split_sentence:
try:
ids[sentence_index][index_counter] = wordsList.index(word)
except ValueError:
ids[sentence_index][index_counter] = UNKNOWM
index_counter = index_counter + 1
if index_counter >= maxSeqLength:
break
def get_ids(input_file, output_file):
positive, negative, neutral = read_file(input_file)
num_files = len(positive) + len(negative) + len(neutral)
ids = np.zeros((num_files, maxSeqLength), dtype='int32')
sentence_index = 0
for sentence in positive:
print("Processing new positive record", sentence_index)
get_sentence_ids(sentence, ids, sentence_index)
sentence_index = sentence_index + 1
for sentence in negative:
print("Processing new negative record", sentence_index)
get_sentence_ids(sentence, ids, sentence_index)
sentence_index = sentence_index + 1
for sentence in neutral:
print("Processing new neutral record", sentence_index)
get_sentence_ids(sentence, ids, sentence_index)
sentence_index = sentence_index + 1
np.save(output_file, ids)
print("Save successfully.")
将 id 矩阵保存以后,后面需要的时候直接load就可以了。
test_ids = np.load('my_idsMatrix.npy')
下面就可以着手开始训练了。
首先定义一些参数:
batchSize = 24 lstmUnits = 64 numClasses = 3 iterations = 100000
每一个训练块取 24 条记录,即 24 个句子。
我使用的是 RNN 的 LSTM 模型,训练单元是 64。
分类是分成 3 类。
迭代 100000 次。
定义一个从训练集中随机抽取训练样本的函数。
def get_train_batch():
accurate_label = []
array = np.zeros([batch_size, max_sequence_length])
for index in range(batch_size):
if index % 3 == 0:
num = randint(1, 3646)
accurate_label.append([1, 0, 0])
elif index % 3 == 1:
num = randint(3647, 5107)
accurate_label.append([0, 1, 0])
else:
num = randint(5108, 9683)
accurate_label.append([0, 0, 1])
array[index] = test_ids[num - 1:num]
return array, accurate_label
def get_validate_batch():
accurate_label = []
array = np.zeros([batch_size, max_sequence_length])
for index in range(batch_size):
num = randint(1, 1654)
if num <= 579:
accurate_label.append([1, 0, 0])
elif num <= 921:
accurate_label.append([0, 1, 0])
else:
accurate_label.append([0, 0, 1])
array[index] = test_ids[num - 1:num]
return array, accurate_label
在这个函数中,index从 0 取到batch_size即 24,根据index被 3 除的余数决定取哪一类标签的样本,这样就保证了每个样本都被平均地取到 8 个。
例如,如果index被 3 整除,那么就在所有 positive 的样本中取,positive 的样本一共 3646 个,因此,在这个范围内随机取一个,加入到array中,即array[index] = test_ids[num - 1:num],并记录当前的样本的标签是属于 positive 的,即accurate_label.append([1, 0, 0])。
对于 negative,随机的范围就是 3647 到 5107,对于 neutral,随机的范围就是 5108 到 9683。
类似的,验证集和测试集也是一样的。
但是对于验证集和测试集,不需要平均地取不同的分类,只需要一次随机。
例如对于验证集,一共 1654 条记录,就只随机一次,然后将这个记录添加进array,并根据随机数的大小判断是哪一个分类。
对于测试集,没有标签字段,这一点下面会处理。
拿到了训练样本,下面就可以训练了。
为了便于观测结果,我使用了 TensorBoard 来做可视化,这样就可以在 http://localhost:6006 查看训练过程中的准确率和损失值的变化。
tf.reset_default_graph() labels = tf.placeholder(tf.float32, [batch_size, numClasses]) input_data = tf.placeholder(tf.int32, [batch_size, max_sequence_length]) data = tf.Variable(tf.zeros([batch_size, max_sequence_length, numDimensions]), dtype=tf.float32) lstm_cell = tf.contrib.rnn.BasicLSTMCell(lstmUnits) lstm_cell = tf.contrib.rnn.DropoutWrapper(cell=lstm_cell, output_keep_prob=0.75) value, _ = tf.nn.dynamic_rnn(lstm_cell, data, dtype=tf.float32)
这里用了 Dropout,就是随机地丢弃一些神经元,降低计算的规模。
在做了一些必要的初始化以后,下面一一赋值。
weight = tf.Variable(tf.truncated_normal([lstmUnits, numClasses]))
bias = tf.Variable(tf.constant(0.1, shape=[numClasses])
value = tf.transpose(value, [1, 0, 2])
last = tf.gather(value, int(value.get_shape()[0]) - 1)
prediction = (tf.matmul(last, weight) + bias)
由此,prediction就是得到的预测矩阵,该矩阵中每一个值表示属于该分类的可能性的大小,那么,取最大值的下标就可以作为预测得到的分类。
如果预测得到的分类与真实的标签一致,就显然是学习成功的。
correctPred = tf.equal(tf.argmax(prediction, 1), tf.argmax(labels, 1))
这句话做的就是,将prediction的结果,与真正的labels做比较,看看他们各自的最大值所对应的下标argmax(args, 1)是不是相等。
然后直接用 TensorFlow 提供的方法计算准确率和损失,不需要自己计算了。
accuracy = tf.reduce_mean(tf.cast(correctPred, tf.float32)) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=labels))
这里的优化器用的是
optimizer = tf.train.AdamOptimizer().minimize(loss)
据说 AdamOptimizer 是最好的优化器。
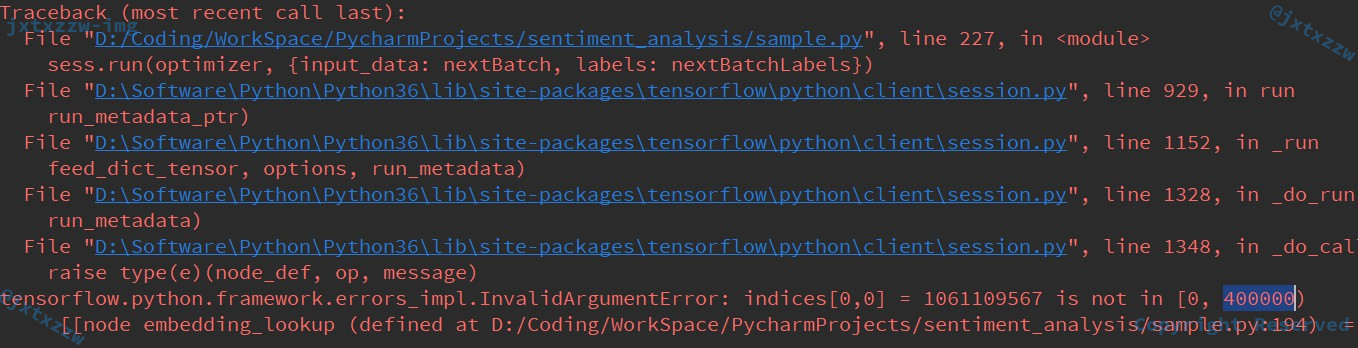
训练的时候有一个坑,我在这里卡住了很久。
可以看到始终会报这个错误。
这是因为一开始我上面处理ids的时候用的UNKNOWN用的是 0x3F3F3F3F,我想用一个值表示无穷大来作为不确定值。
但是可以看到,这里他一定要要求范围只在 [0,400000),所以,只能把UNKNOWN改为 399999,并重新计算ids。
又是漫长的等待……
定期输出一下,便于观察:
tf.summary.scalar('Loss', loss)
tf.summary.scalar('Accuracy', accuracy)
merged = tf.summary.merge_all()
logdir = "tensorboard/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") + "/"
writer = tf.summary.FileWriter(logdir, sess.graph)
输出到 TensorBoard 做可视化。

tensorboard --logdir=tensorboard
启动可视化窗口。
这个训练的过程是非常漫长的,为了避免训练过程中突发异常导致前面的都白训练了,我们应该每隔一定时间就把训练结果保存一下。
这里使用了ckpt保存,每隔 1000 次训练,就将当前的训练结果保存下来。
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(iterations):
#Next Batch of reviews
nextBatch, nextBatchLabels = get_train_batch()
sess.run(optimizer, {input_data: nextBatch, labels: nextBatchLabels})
# Write summary to Tensorboard
if i % 50 == 0:
summary = sess.run(merged, {input_data: nextBatch, labels: nextBatchLabels})
writer.add_summary(summary, i)
# Save the network every 10,000 training iterations
if i % 1000 == 0 and i != 0:
save_path = saver.save(sess, "models/pretrained_lstm.ckpt", global_step=i)
print("saved to %s" % save_path)
writer.close()
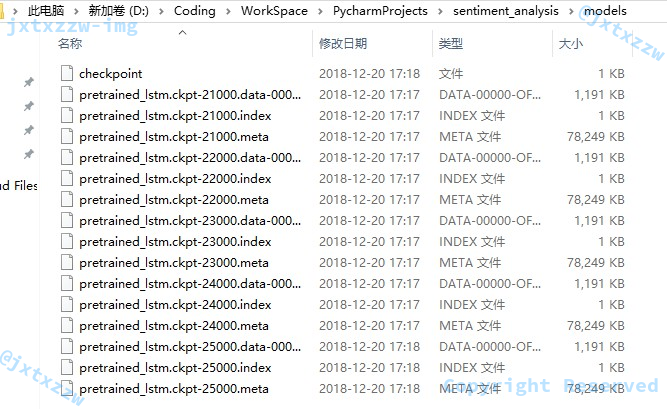
可以看到,每隔 1000 个训练,就保存了一次 CheckPoint,而且可以看到,会自动地删除旧的检查点,只保留最近的 5 个。
程序正常结束。
看一下精度。
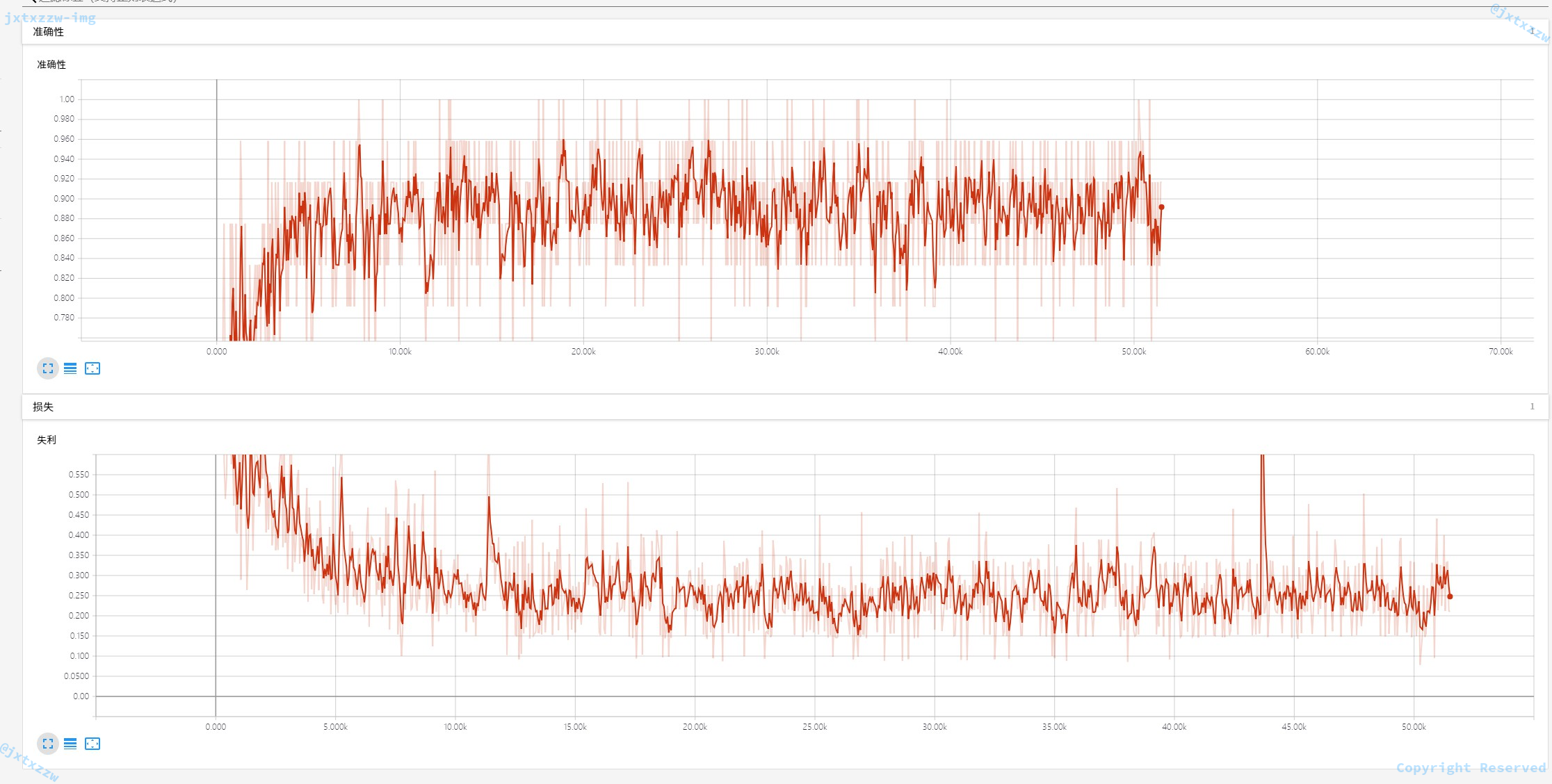
这是训练到 50% 时候。
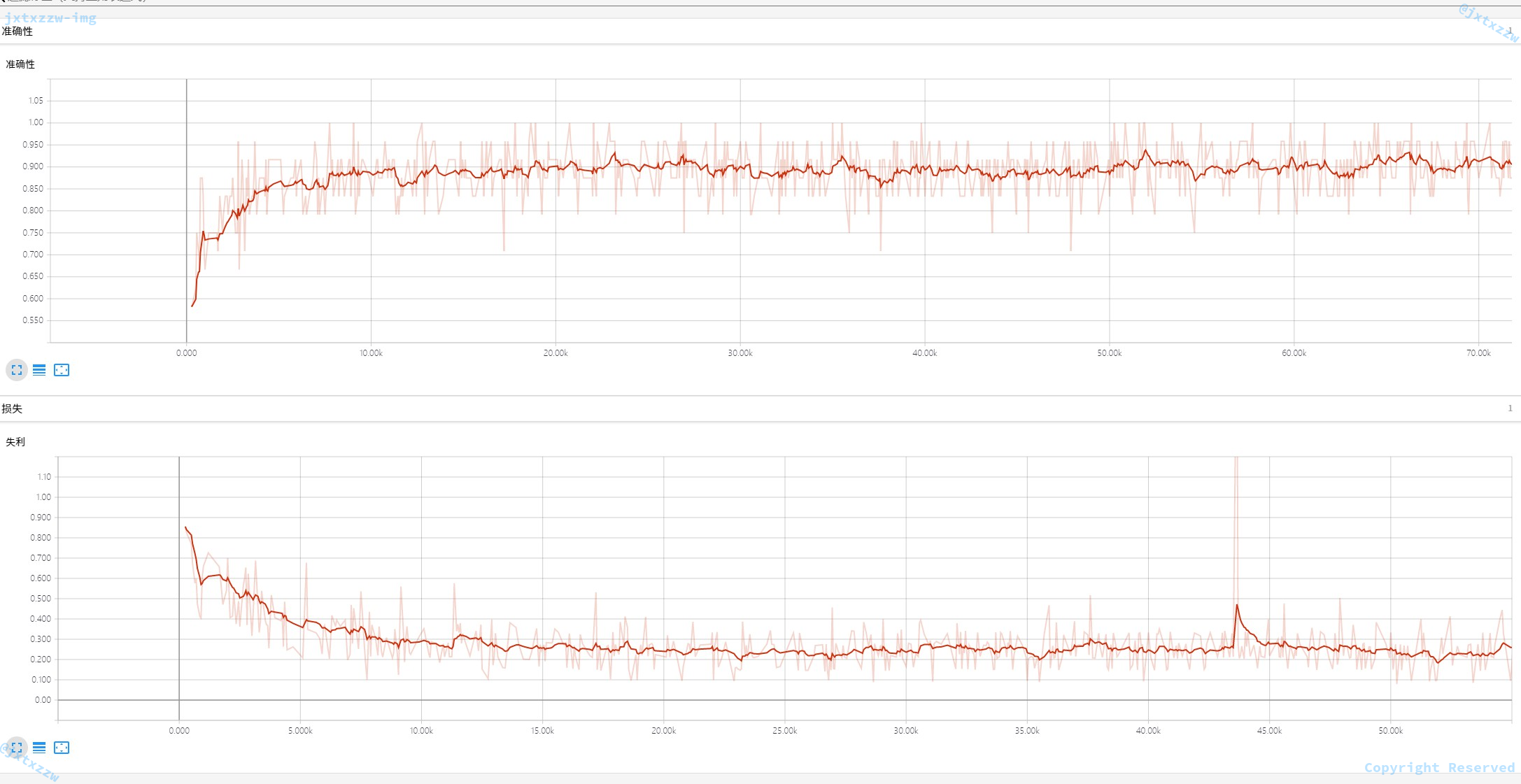
这是去除了一些异常的点以后看到的。
可以看到,训练的准确率基本在 90% 左右。
下面就可以开始测试了,在测试之前,我们先对准确率做一个验证。
假设验证集的ids已经保存,并已经导入。
那么下面直接从检查点载入最新的训练结果:
sess = tf.InteractiveSession()
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('models'))
由于验证数据是直接从ids读入的,所以调用上面的get_validate_batcher就可以传给 TensorFlow 做预测,并计算准确率。
iterations = 100
total = 0
for i in range(iterations):
print("i=", i, " ", end='')
nextBatch, nextBatchLabels = get_validate_batch()
print("Accuracy for this batch:", (sess.run(accuracy, {input_data: nextBatch, labels: nextBatchLabels})) * 100)
total += (sess.run(accuracy, {input_data: nextBatch, labels: nextBatchLabels})) * 100
print("Average Accuracy:", total / iterations)
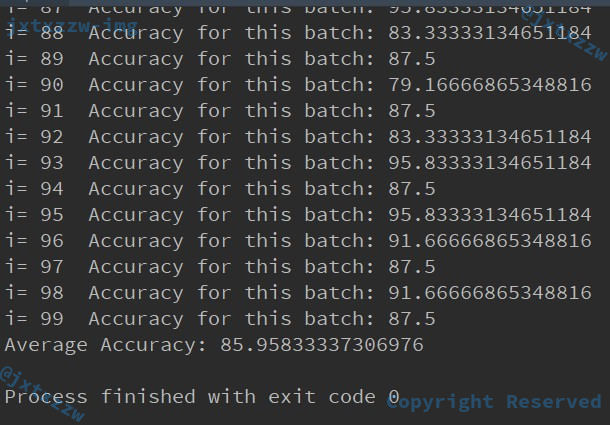
可以看到,验证下来的准确率有接近 86%。
这是可以接受的。
毕竟,这个样本是 Twitter 上的发言,很多用户的留言本来就是情感信息不明确的,甚至有可能有些人会正话反说、妙用隐喻,那就对机器学习带来了极大的难度,对于这类涉及到人类情感的,我认为 90% 已经很高了。
当然,如果只是用来训练物品的,判断这是杯子还是猫,是狗还是车,那么,准确率达到 98% 也是不足为奇的。

当然,考虑到我们进行的是 3 分类,即 positive、negative 和 neutral。
如果我们进行 2 分类,效果会不会好一点?
从现实生活中的情况考虑,人类的情感是非常复杂的,无奈、气愤、平淡、伤心、兴奋、甚至一种难以言表的非常微妙的喜悦……
但是如果我们把问题简化成非黑即白的,也就是说,除非是我很能看出你是高兴的,那我把你认为是 positive 的(事实上这一点还是非常容易看出来的,一个人是非常高兴的),否则,一概认为是 negative 的。
尝试一下。
首先,将numClasses改成 2,然后把所有的 [1, 0, 0] 改成 [1, 0],而所有的 [0, 1, 0] 和 [0, 0, 1] 都改成 [0, 1]。
再次学习,准确率接近 100%。
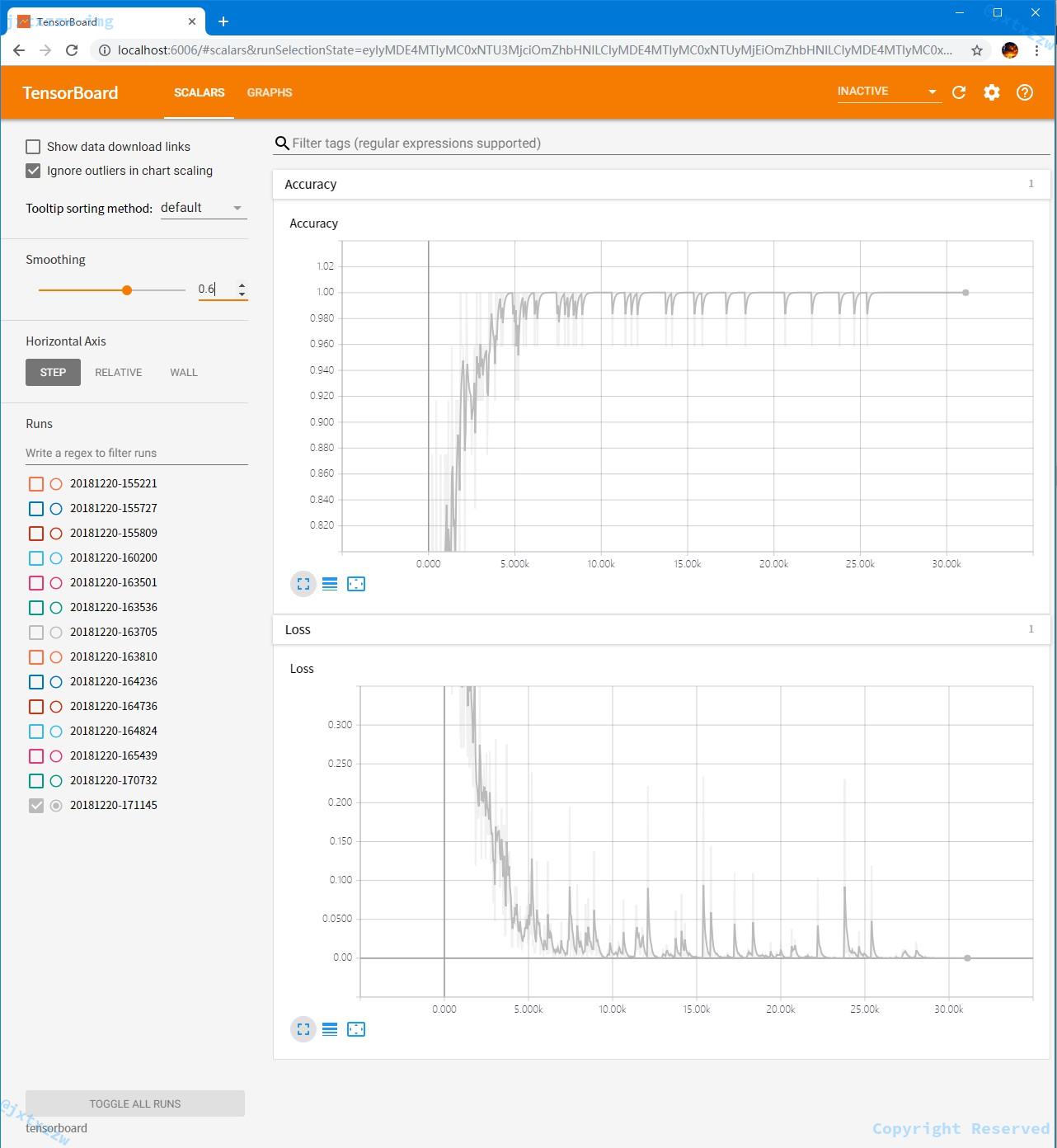


损失也非常小。
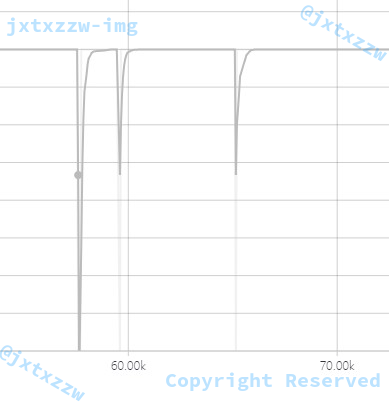
有部分异常点,这是显然的,因为毕竟存在大量的中立情绪,显然这个世界不是非黑即白的。
而这一结果,复现了《perform-sentiment-analysis-with-lstms-using-tensorflow》这篇论文中,对电影评级的训练准确度。
最后是处理测试的部分,由于测试部分没有标签,所以很多函数需要改。
但是改动的也很少,只要把所有与标签处理相关的部分去掉就可以了:
read_file就只需要依次读入,然后保存,不需要按标签分 3 个列表保存- 后面处理
ids的时候也只需要全部遍历计算,不需要分不同的标签 - 取
Batcher的时候只需要完全随机 - 最后得到结果,只需要找出最大值所在的下标,不需要与标签做比对计算准确率
这一部分的修改比较简单,这里就不给出代码了,可以去看我的完整代码。
此区域的内容需评论后可见
import numpy as np
wordsList = np.load(‘wordsList.npy’)
wordsList = wordsList.tolist()
wordsList = [word.decode(‘UTF-8’) for word in wordsList]
wordVectors = np.load(‘wordVectors.npy’)
报错ValueError: cannot reshape array of size 11232 into shape (400000,)
win10环境,请问是环境不对吗?有什么解决办法吗?
@eweq不知道为什么你的评论直接出现在了垃圾评论中……非常抱歉。
环境的问题应该可以排除,我刚才在 win10 和 centos7 都测试了,应该是没有问题的。看起来你下载的数据集只有 11232 个数据,似乎是没有下载完整。跟你确认一下文件的大小,wordsList.npy 为 26M,wordVectors.npy 为 76M,我稍后重新上传一次,麻烦你重新下载,看看是不是解决问题了。
最后,大佬交换友链嘛~~~
@凝神长老谢谢,我再试一下。我只是个新手,希望借这个项目实践一下。。
大佬愿意加我的友链当然会同意。
http://www.woria.xyz
@凝神长老您新上传的文件可以正常使用了,谢谢。
@eweq好的,加油。
@eweq一般来说,这些文件可能是特定项目或数据集的一部分。你可以尝试在相应的项目或数据集的官方网站或资源库中查找这些文件。通常,这些文件会在项目的文档或下载页面中提供。
如果你知道这些文件属于哪个项目或数据集,你可以尝试在搜索引擎中搜索相关的关键词,找到官方网站或资源库。
請問中間是不是少了一個function沒放上去 ex: def cleanSentences():
@Seraph是的,这个 function 主要用来修剪句子,实现方法比较灵活,例如可以使用最简单的 trim() 等。文中 function 的 definition 如下:
import re strip_special_chars = re.compile("[^A-Za-z0-9 ]+") def clean_sentences(string): string = string.lower().replace("", " ") return re.sub(strip_special_chars, "", string.lower())
@Seraph可以t = np.load(‘wordsList.npy’)
wordsList = wordsList.tolist()
wordsList = [word.decode(‘UTF-8’) for word in wordsList]
wordVectors = np.load(‘wordVectors.npy’)
请问补0不会影响内容吗?
@茶风林丶不会。因为事实上的句子长度是不足n位的,为了补足n位就必须填充一个数字,而选择0作为填充的数字,这样补上的就只是一个占位符,不会引入额外的信息(例如不能补10、补无穷大),而由矩阵计算的性质可知,补0不会影响结果。
@凝神长老懂了,谢谢!
impot numpy as np
wordsList = np.load(‘wordsList.npy’)
wordsList = wordsList.tolist()
wordsList = [word.decode(‘UTF-8’) for word in wordsList]
wordVectors = np.load(‘wordVectors.npy’)
求需要wordslist wordvectors npy
zab
请问train.txt,dev.txt和dev_idsMatrix.npy三个文件在哪能下到?
另外,有这个项目的全部代码和所有的数据文件么?
谢谢!
@taoyuan一般来说,这些文件可能是特定项目或数据集的一部分。你可以尝试在相应的项目或数据集的官方网站或资源库中查找这些文件。通常,这些文件会在项目的文档或下载页面中提供。
如果你知道这些文件属于哪个项目或数据集,你可以尝试在搜索引擎中搜索相关的关键词,找到官方网站或资源库。
我是新手,只能一步一步走。
请问train.txt,dev.txt和train_idsMatrix.npy三个文件哪里能下载到?
请问有没有可以下载到这个项目全部数据文件和代码的链接?
谢谢!
请问大佬train.txt,dev.txt和train_idsMatrix.npy文件在哪?我是新手,只能一步一步走。
有没有完整的代码和数据包直接下载的?
谢谢您!
请问train.txt,dev.txt以及train_idsMatrix.npy文件在哪,我是新手,现在只能一步一步走,谢谢!
或者有没有这个项目的完整的代码和数据包可以下载?
谢谢您!
请问是否有针对Tensorflow 2.x的代码
请问是否有针对Tensorflow 2.x的相关代码
写得很详尽,感谢教程!
test