

源代码
你可以在这里查看源代码: https://gitlab.jxtxzzw.com/jxtxzzw/compiler
视频
你可以在这里查看视频,时长约为 30 小时: https://www.bilibili.com/video/av75077580/
| 学校 | 华东师范大学 |
| 专业 | 计算机科学与技术 |
| 课程 | 编译原理实践 |
| 教师 | 钱莹 |
| 年份 | 2019年秋 |
要求其实可以分为这么几个步骤:
- 读入 CX 代码,各种词法分析、语法分析,把源代码变成一棵抽象语法树。
- 遍历抽象语法树,依次翻译为 p-code。
- (如果必要,修改 Pmachine 语法并重新编译后,)将 p-code 运行在 Pmachine 上。
我不可能从零开始讲怎么自上而下、自下而上地构建语法树,这个太花时间了,所以有些地方我默认你已经掌握,我会简单说,但是所有必要的地方我都会提及。
首先假设你已经有了一棵抽象语法树 AST。
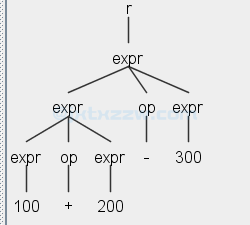
那么,如果存在一种遍历方法,能够以此访问各个节点,只需要在访问特定节点的时候输出一些东西即可。
例如对于 100+200 这个表达式,要变成 p-code,只需要先把 100 入栈,即 ldc i 100(压入一个整数 100),再把 200 入栈,即 ldc i 200,然后将栈顶的两个元素(出栈并)做整数的加法,得到的结果存放在栈顶,即 add i。
因此,如果在遍历这个部分的时候,程序能够输出 ldc i 100\n ldc i 200\n add i\n 就完成任务了。
为了把问题说清楚,不妨假设我们现在已经存在了一个 Visitor,这个 Visitor 会依次遍历 AST,并且保证一定的访问次序(例如,加法是左结合的访问顺序),然后在遍历到不同的成分的时候,执行不同的函数,例如它在遍历到当前是数字的时候,就会执行 visitNumber(),它在执行到表达式的时候,就会执行 visitCalc()。
至于这个 Visitor 怎么来的,后面再说。
如上文说的,在遍历到数字 x 的时候,期望的结果就是输出一个“把当前数字 x 压入栈顶”的 p-code 代码,于是,输出 ldc i ctx.NUM().getText() 即可。
在下面这段代码中,visitNumber() 就是做了这件事情,从上下文中获取当前数字的内容,然后按格式输出。
需要说明的是,这里只是为了说明问题,所以遇到数字就直接 System.out.println() 了,也没有在意返回值的事情,直接 return ""。
@Override public String visitNumber(ExpressionTestParser.NumberContext ctx) {
System.out.println("ldc i " + ctx.NUM().getText());
return "";
}
类似的,有:
@Override public String visitCalc(ExpressionTestParser.CalcContext ctx) {
visit(ctx.expr(0));
visit(ctx.expr(1));
switch (ctx.op.getType()) {
case ExpressionTestParser.ADD:
System.out.println("add i");
break;
case ExpressionTestParser.SUB:
System.out.println("sub i");
break;
case ExpressionTestParser.MUL:
System.out.println("mul i");
break;
case ExpressionTestParser.DIV:
System.out.println("div i");
break;
}
return "";
}
这里需要说明的有 2 个部分。
一,由于左右表达式可能分别为嵌套了的子表达式,所以需要依次遍历左右子表达式并输出他们的代码。
二,ctx.op 是运算符,根据运算符的不同,进入一个分支判断,决定输出最后一行的运算代码。
这样一来,我们就可以在 Main 函数简单的写上:
Visitor v = new Visitor();;
v.visit(tree);
System.out.println("hlt");
运行,输入表达式 120+330+50,然后构造抽象语法树,并调用上面的 Main 函数,可以发现输出了
ldc i 120 ldc i 330 add i ldc i 50 add i
最后我加上了 out i 和 hlt 分别输出结果和停止程序。
将输出的内容保存到 1.p 并用 Pmachine 执行,得到如图所示的结果。
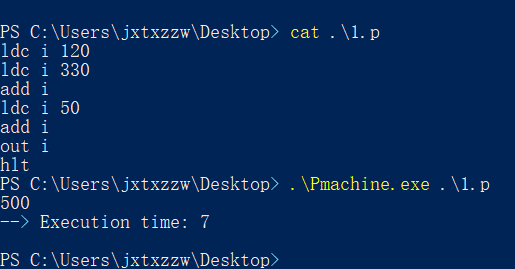
看到输出了正确的结果 500。
现在的关键在于怎么实现这个访问的过程。
所谓的访问过程,包括抽象语法树的建立,以及遍历并输出代码的部分。
问题一个个解决。
我是用 Java 写的,但其实没有用到什么特性,如果你硬要说类的话,C++ 也可以写类,甚至你可以用 C 的结构体来作为一个个类。因此,你用 C 还是 C++ 什么的,也完全是 OK 的。不过有一个坑我已经踩过了,别用 JavaScript。
首先定义一个接口,Statement,这个接口有一个默认的方法 compile(),他接受一个 ParseTree 表示当前的语句,返回一个 String 表示编译后的代码。
public interface Statement {
String compile();
}
解释一下 tree。
你可以把 tree 当做一个数据结构,对于非叶子节点,tree 表示当前的根,它有一个或多个孩子,孩子可能是叶子节点也可能是非叶子节点,对于叶子节点,可以把它当做终结符。
需要指出的是,可以当做终结符的具体含义是,如果当前根拥有 3 个孩子,分别是 INTEGER、ADD、INTEGER,显然这是一个 x+y 的表达式,但是在语法定义中,ADD 是 “+” 是一个终结符,而 INTEGER 事实上可以继续被展开成 (+|-)?[1-9]\d*,但是由于 INTEGER 的含义过于直白,就把它当做一个终结符也没事。
我保证了 tree 至少有 2 个成员函数,一个是 getChildCount(),返回孩子个数,一个是 getChild(int x) 表示获取第 x 个孩子。事实上它还有其他便于 coding 的方法,不过最主要的还是这两个。
其次,Expression 是一个抽象类,它实现了 Statement 接口,这意味着表达式也可以通过 compile() 方法得到编译后的代码。除此之外,它还有一个 BaseType,表示表达式的类型,是 int 还是 boolean 等,这是为了之后做表达式的运算的时候,要保持类型一致。
BaseType 在这里是一个自己定义的类,由 String name 和 String code 组成,其中 name 表示类型的名字,是 human-readable 的,例如 int,而 code 表示类型的 p-code 代码,例如 int 对应的就是 i。
我没想好到底 BaseType 还要不要一个 size,看需要就加吧。
Expression 类还可以增加一些其他的成员,例如 ParseTree,这个可以看具体是什么表达式,具体做什么拓展。这个下面会说到。
abstract class Expression implements Statement {
private BaseType baseType;
Expression(BaseType baseType) {
this.baseType = baseType;
}
public BaseType getBaseType() {
return baseType;
}
}
public class BaseType {
private String name;
private String code;
public BaseType(String name, String code) {
this.name = name;
this.code = code;
}
public String getCode() {
return code;
}
public String getName() {
return name;
}
}
我在 Expression 下新定义了一个子类叫做 ArithmeticExpression,这是算数表达式,它继承了 Expression。
显然,构造的时候需要保留一个 BaseType 并记录 ParseTree。由于我这里只是做一个简单的提要,就默认只算 int 吧,那于是 baseType 就是 new BaseType("int", "i");。
另外需要 @Override 那个 compile() 方法。
在继续之前,现在需要梳理一下了———我们有了一个接口 Statement,一个抽象类 Expression,一个类 ArithmeticExpression。
那我现在想要处理赋值表达式应该怎么办呢?没错,从 Expression 派生出一个 AssignmentExpression 子类。
那我现在想要处理变量怎么办呢?一种可能的做法是,定义一个抽象类 Variable 实现 Statement 接口。我没想好,可能会搞一个 Declaration 的抽象类。
由于都是实现了 Statement 接口,所以只需要为每一个类分别实现属于自己的 compile() 就可以了。
写到这里的时候我意识到,Statement 和 Declaration 好像是平行的。而且接口的名字应该像 Comparable 这样,那这个接口就应该叫做 Compilerable?
算了,以后再考虑这些 Clean Code。
有了这些类,我们就可以做一些事情了。
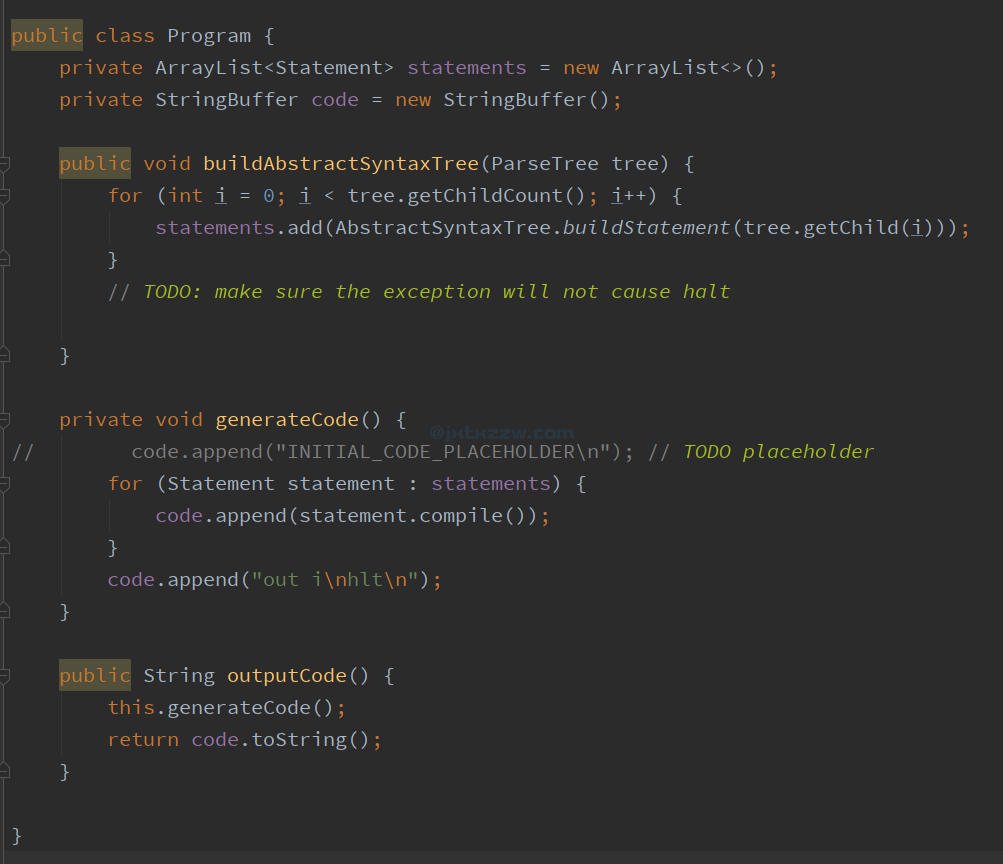
定义一个类叫做 Program,这个 Program 就是我们的程序,那么它应该要做两件事情。
第一件事情,读输入,并构造抽象语法树。
public void buildAbstractSyntaxTree(ParseTree tree) {
for (int i = 0; i < tree.getChildCount(); i++) {
statements.add(AbstractSyntaxTree.buildStatement(tree.getChild(i)));
}
}
第二件事情,遍历抽象语法树,并输出编译后的 code。
private void generateCode() {
for (Statement statement : statements) {
code.append(statement.compile());
}
}
public String outputCode() {
this.generateCode();
return code.toString();
}
这两段代码都是自解释的,想必不需要再详细说明了。
需要注意的是,由于 buildStatement 接受的是一个 tree,而返回值是 Statement 接口,因此,直接加到 ArrayList 就可以了。而又由于这个 list 中所有的元素都是可以 compile() 的,所以输出代码也变得非常简单。
如果有了这样一个类,那么主函数就变得非常简单。
假设我们已经得到了一个 ParseTree,那么只需要简单的 3 句就可以完成整个编译过程。
Program p = new Program(); p.buildAbstractSyntaxTree(tree); System.out.println(p.outputCode());
于是,你发现了,所有的重头戏,其实只剩下了如何定义那些类,以及,每一个类的 compile() 具体应该怎么写。
我下面就以 ArithmeticExpression 为例,简单说说。
定义一个简单的语法 ExpressionTest。
grammar ExpressionTest;
r: expr;
expr: expr op expr # arithmetic
| NUM # number
;
op: ADD | SUB | MUL | DIV;
NUM: INT;
INT: [0-9]+;
ADD: '+';
SUB: '-';
MUL: '*';
DIV: '/';
WS: [ \t\r\n]+ -> skip;
这段语法应该也写的非常简单了,规则是 expr,expr -> expr op expr | NUM。
其中 op 是加减乘除,分别对应四个符号。NUM 在这里只表示 INT,INT 是 [0-9]+。
跳过所有的 WhiteSpace。
注意这段是不完备的,应该还要加很多东西。
语法清晰了以后,可以去定义 ArithmeticExpression 这个类了,构造函数与上文说的一样。
ArithmeticExpression(BaseType baseType, ParseTree tree) {
super(baseType);
this.tree = tree; // TODO: do we really need the whole tree? or can just use built expression
}
注意这里的一个 TODO:是不是需要保留整个 ParseTree?这个问题我留到下面再讨论,不过我觉得到目前为止,我想表达的意思已经传达的够清楚了。
另外还有一个 compile()。
@Override
public String compile() {
String code = "";
// TODO: use recursively build here, 'cause we can just compile 1+2 but not 1+2+3 now
code += "ldc i " + tree.getChild(0).getText() + "\n";
code += "ldc i " + tree.getChild(2).getText() + "\n";
// TODO: better change the String compare to token == in lexer
ParseTree token = (ParseTree) tree.getChild(1).getPayload();
switch (token.getText()) {
case "+":
code += "add i \n";
break;
case "-":
code += "sub i \n";
break;
case "*":
code += "mul i \n";
break;
case "/":
code += "div i \n";
break;
// TODO: default branch
}
return code;
}
首先这里也是非常简陋的,初始化 code = "" 后,先后输出 idc i 开头的左右表达式的值。
需要指出的是,这里应该是要递归地访问左右子表达式,即,build,而不是直接输出,否则就会把 100+200+300 输出成 ldc i 100+200\n ldc i 300\n add i\n 这个样子。
在输出了左右子表达式的代码以后,就要对此进行运算了,于是,通过判断 token 的类型,决定输出 add 还是 sub 或者其他。
需要指出的是,这里为了说明问题,直接判断了 getText() 是不是 +-*/。其实最好的做法,应该是这里获取 token.getType(),并判断其值是不是等于 ExpressionTestLexer.ADD 或者 ExpressionTestLexer.DIV 之类的。这样的话在修改语法以后,不需要修改这里的代码,实现了松耦合。
另外,这里完全没有做出错处理,常见的出错处理有,左右子表达式类型不一致的时候,抛出异常,运算符进入 default branch 的时候,抛出异常……
问题涉及到变量的时候会更加复杂——变量未定义?未初始化?那就会有更多的异常。
所以简单小结一下,这段 demo 的问题还有:
- 左右子表达式需要递归地访问。
- 需要使用 token 的 type 来确定运算符。
- 出错处理。
如果你看到这里都能完全理解,那么,我们可以继续往下了,否则,建议你重新读一遍上面的内容。
先来解决上面这三个问题。简单说一下思路。
第一个,派生一个 ConstantExpression 子类。可以判断 childCount 是不是等于 3,如果是,则对左右子表达式分别 buildArithematicExpression,否则判断是不是等于 1,如果是等于 1,直接 buildConstantExpression,buildConstantExpression 的时候的 compile() 就是返回 getText()。
第二个,直接把 op 当做终结符 OP,并直接把 ADD|SUB 写在语法规则中。
第三个,勤判断,勤抛异常。
最后,在 Test.java 里面,我们只需要简单的把输入 input,依次经过词法分析、语法分析,然后,直接用 Program 来 build 和 compile 即可。
ParseTree tree = parser.r(); Program p = new Program(); p.buildAbstractSyntaxTree(tree); System.out.println(p.outputCode());
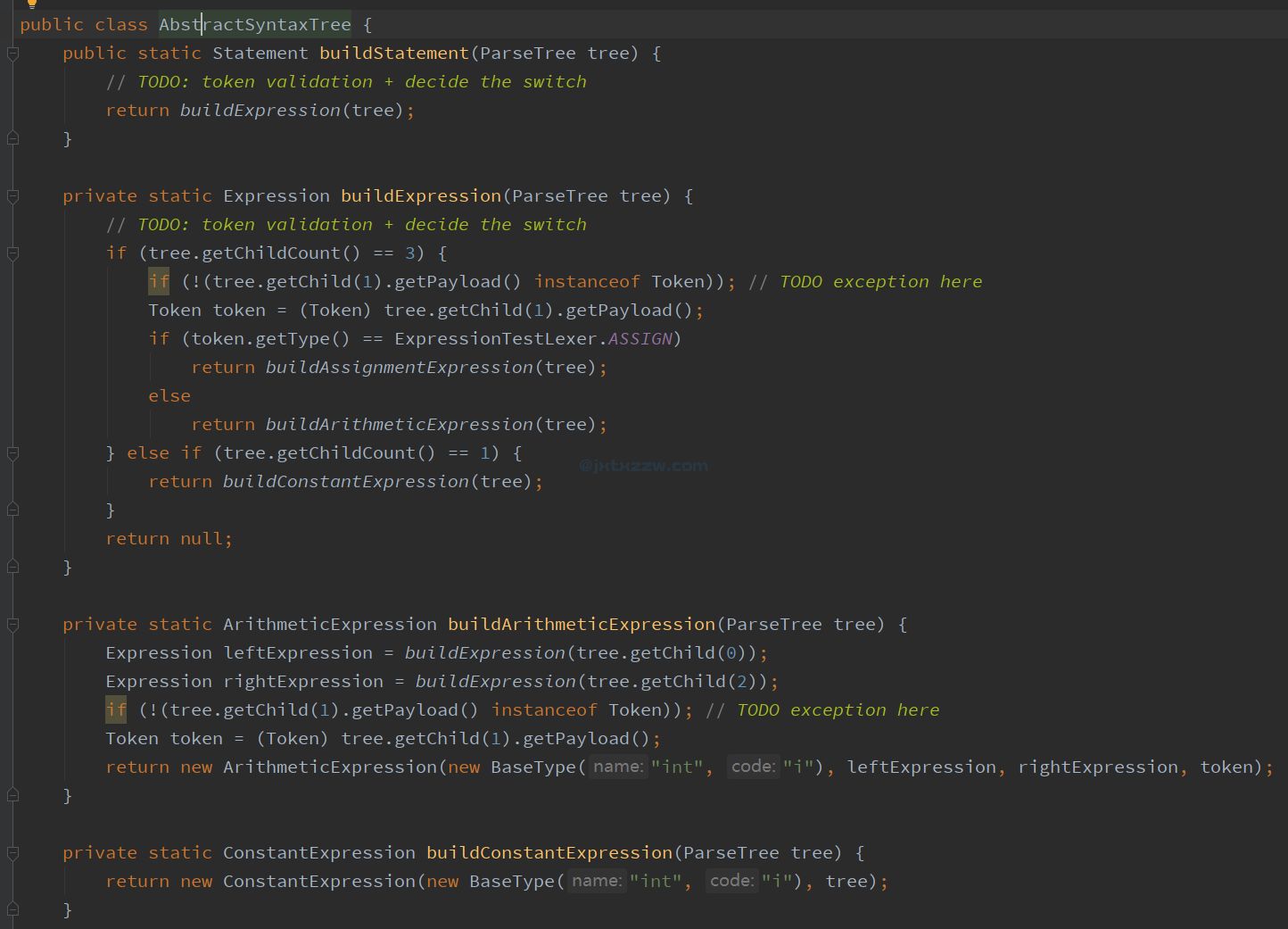
具体来说,在我拿到一个 tree 的时候,我判断它孩子的个数,如果是 3 个孩子,说明他是一个算数表达式,否则,他是一个常数表达式。
if (tree.getChildCount() == 3) {
return buildArithmeticExpression(tree);
} else if (tree.getChildCount() == 1) {
return buildConstantExpression(tree);
}
ArithmeticExpression 的定义如上文。ConstantExpression 的定义是类似的,构造的时候接受一个 tree,而 compile() 则输出 ldc i X 的形式。
public class ConstantExpression extends Expression {
private ParseTree tree;
ConstantExpression(BaseType baseType, ParseTree tree) {
super(baseType);
this.tree = tree;
}
@Override
public String compile() {
return "ldc " + getBaseType().getCode() + " " + tree.getChild(0).getText() + "\n";
}
}
在上面的代码中,我们的 buildArithmeticExpression 是直接做了这样一件事情,那就是 new ArithmeticExpression(baseType, tree)。
并且我留下了一个疑问:是不是需要保留整个 ParseTree?
现在我们把这件事情想的透彻一点,保留整棵树是不是必要的?有没有可能只保留左右子表达式就够了,而且会更容易操作?
尝试修改定义:
public class ArithmeticExpression extends Expression {
private Expression leftExpression;
private Expression rightExpression;
private Token token;
ArithmeticExpression(BaseType baseType, Expression leftExpression, Expression rightExpression, Token token) {
super(baseType);
this.leftExpression = leftExpression;
this.rightExpression = rightExpression;
this.token = token;
}
}
如此一来,就能够把 Arithmetic 和 Constant 区分开了。
在 AST 中,只提供一个公共的方法:
public class AbstractSyntaxTree {
public static Statement buildStatement(ParseTree tree) {
// TODO: token validation + decide the switch
return buildExpression(tree);
}
}
其余的都是私有的方法。
private static Expression buildExpression(ParseTree tree) {
// TODO: token validation + decide the switch
if (tree.getChildCount() == 3) {
return buildArithmeticExpression(tree);
} else if (tree.getChildCount() == 1) {
return buildConstantExpression(tree);
}
return null;
}
private static ArithmeticExpression buildArithmeticExpression(ParseTree tree) {
Expression leftExpression = buildExpression(tree.getChild(0));
Expression rightExpression = buildExpression(tree.getChild(2));
if (!(tree.getChild(1).getPayload() instanceof Token)); // TODO exception here
Token token = (Token) tree.getChild(1).getPayload();
return new ArithmeticExpression(new BaseType("int", "i"), leftExpression, rightExpression, token);
}
private static ConstantExpression buildConstantExpression(ParseTree tree) {
return new ConstantExpression(new BaseType("int", "i"), tree);
}
首先,buildStatement 在我目前所涉及的语法中,只会进入 buildExpression。
而进入了表达式的构造,就需要判断孩子的个数。
如果是只有一个孩子,那么进入 buildConstantExpression,如上文,直接 new 一个对象即可。
如果有 3 个孩子,首先要递归 build 第 0 和第 2 个孩子,用的是 buildExpression 这个方法,之后判断第 1 个孩子是不是加减乘除,如果是,就把 token 和刚才 build 出来的 Expression 一起 new 一个 ArithmeticExpression 出来,如果不是,那么就进入出错处理,例如,三个孩子是 10、20、30,而不是 10、+、20。
之后如果想要再加别的表达式,例如赋值表达式怎么办?
赋值表达式也是有 3 个孩子:左边的是被赋值的变量,中间的是赋值号,右边的是一个(不知道是什么也许是 Arithmetic 也许是 Constant 也许是其他的 Expression 的子类的)表达式。
但是这并不妨碍我们修改 buildExpression 的代码,通过这样的方式依然可以唯一确定具体的类型,并且出错处理是完备的:
if (tree.getChildCount() == 3) {
if (!(tree.getChild(1).getPayload() instanceof Token)); // TODO exception here
Token token = (Token) tree.getChild(1).getPayload();
if (token.getType() == ExpressionTestLexer.ASSIGN)
return buildAssignmentExpression(tree);
else
return buildArithmeticExpression(tree);
} else if (tree.getChildCount() == 1) {
return buildConstantExpression(tree);
}
为了文章的完整性,这里给出 AssignmentExpression 类的定义和 buildAssignment 的实现。
private static AssignmentExpression buildAssignmentExpression(ParseTree tree) {
Expression expression = buildExpression(tree.getChild(2));
System.out.println(expression);
return new AssignmentExpression(new BaseType("int", "i"), expression);
}
private Expression expression;
AssignmentExpression(BaseType baseType, Expression expression) {
super(baseType);
this.expression = expression;
}
@Override
public String compile() {
String code = expression.compile();
code += "str " + getBaseType().getCode() + " 0 " + "get_var_address_placeholder" + "\n";
return code;
}
但是请注意,类似 get_var_address_placeholder 这样的内容还需要你们自己去发挥了哦。
现在,请回过头再看一眼这段代码,是不是觉得足够简单了呢?
最后我来说一下符号表。
函数的部分我还没想好怎么写。
Symbol 类比较简单,需要有一个标识符,需要有一个类型,可能还需要一个 size,为今后数组做打算,至于 address 要不要,没想好。
package com.jxtxzzw.compiler.st;
import com.jxtxzzw.compiler.type.BaseType;
public class Symbol {
private String identifier;
private BaseType beseType;
private int address;
public Symbol(String identifier, BaseType beseType, int address) {
this.identifier = identifier;
this.beseType = beseType;
this.address = address;
}
public String getIdentifier() {
return identifier;
}
public BaseType getBeseType() {
return beseType;
}
public int getAddress() {
return address;
}
}
接下来看一眼作用域 Scope。
private Scope parent;
private int allocated;
private HashMap<String, Symbol> symbols = new HashMap<>();
private ArrayList<Scope> scopes = new ArrayList<>();
目前我给了 4 个成员。
不论何时,new 一个新的作用域的时候,一定会有一个唯一的,永远不会变的 parent,所以构造函数只接受一个 parent,newScope() 方法是在当前作用域下开一个子作用域。
public Scope(Scope parent) {
this.parent = parent;
}
public Scope openScope() {
Scope scope = new Scope(this);
scopes.add(scope);
return scope;
}
对于 Global 的 Scope,我定义 parent 为 null,于是有:
private int level() {
int level = 0;
while (parent != null) {
level++;
parent = parent.parent;
}
return level;
}
之后就是一些很显然的方法了,例如计算一共分配了多少内存?即返回 allocated。如果有新的符号被加入,则更新 allocated。
插入和查询符号我用了 HashMap,所以直接 get 和 containsKey 就可以了。如果手动实现的话,大不了一个遍历数组,然后不在就返回 null 嘛。
public void addSymbol(Symbol symbol) {
symbols.put(symbol.getIdentifier(), symbol);
}
public Symbol getSymbol(String identifier) {
return symbols.get(identifier);
}
public boolean containsSymbol(String identifier) {
return symbols.containsKey(identifier);
}
在 SymbolTable 里面,定义一个全局的 Scope,然后开始做事。
梳理一下 CX 的语法规则。
语言最开始就是一对大括号,语句写在大括号里面,所有的 Declaration 都在 Statement 之前。
变量的作用域只在当前的大括号,出了大括号则失效。
大括号中嵌套的大括号可以继续定义变量,定义的变量作用域只在那个大括号中。
如果内层大括号出现外层大括号同名的变量,则在内层大括号使用内层的定义,在内层大括号以外的外层大括号区域使用外层的定义。
于是,一个简单的思路就诞生了:遇到大括号,则开始往 SymbolTable 加符号。
遇到一个符号,看是不是已经存在 containsSymbol,决定是给错误,还是 addSymbol。
重复上面的过程,直到遇到 Statement。
在处理过程中如果遇到嵌套的大括号,则在当前层开启新的 Scope,并重复上面的过程。
由于 containsSymbol 这样的操作是 Scope 的成员函数,所以自然的被限定在了作用域中,不需手动处理同名变量的问题了。
遇到大括号结束的时候,关闭 Scope。关闭的操作指的是 scope = scope.parent。
在查询变量的时候,在当前 scope 查找,如果有,get,否则,向上一层,直到最近原则找到。如果 parent 为 null 还找不到,说明使用了未定义的变量,直接报错。
说完了所有的思路,给一个福利。
我给你们看一下我目前的项目结构。
因为还没做完,而且有些地方没有想明白,所以可能以后会改也说不定。
但是如果你只想继续往下做,那么,你只需要继续增加新的子类,并且扩充 buildStatement() 就可以了。
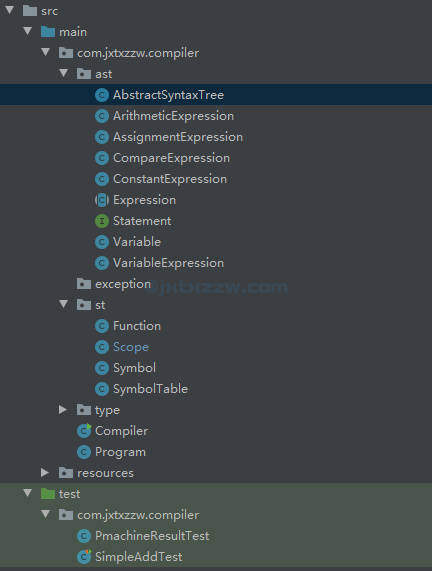
test 是我用了 Junit 来跑测试的,免得每次手动测试了。
最后提醒一下:如果你打算用 LEX 和 YACC,建议你先去了解清楚。因为一旦 LEX 和 YACC 帮你做的事情有点多了以后,可能你只能按照它的思路继续往下写,你可能用不了我的思路了。
想问一下大佬为什么用JavaScript是坑?(虽然作业也不让用,但是好奇)
@yutau类和继承比较混乱,不太好写
@凝神长老这倒是真的,哈哈哈哈哈哈哈
zzw tql