
这篇文章实现的功能不完整,也有错漏的地方,可以参考 CSAPP 这本书的 Shell Lab (Carnegie Mellon University 15-213 课程作业)了解更严谨的 Shell。
该
Shell在我的服务器上运行完全正确CentOS 7.3 64位model name : Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHzMemTotal: 3881076 kB Buffers: 126948 kB如果你的本地环境与我不同(例如你用了
Ubuntu),导致有些命令没法正常运行,不接受任何反驳但是欢迎指出我代码实现上的错误(
ill-implemented)
这次的作业是要求写一个Shell
Shell最基本的功能是能够执行一些命令,例如,ls、cd……
当然也要支持带参数运行
之后要支持重定向(输入<、输出>、追加>>)
奖金问题还有支持管道,支持管道的话有加分
执行命令的基本部分的代码比较简单,就是一个while死循环,解析命令以后fork一个进程并运行
重定向的基本的思路是字符串解析,因为只可能出现一个重定向符号,之后无论出现什么命令都是无效的
管道可以嵌套很多,所以可以用递归实现
难点在于fork以后父进程、子进程序的处理
尤其是当需要支持后台运行(&)的时候,必须严格区分父、子进程
其他的要求例如:
- Basic Shell
- Built-in Commands
- Redirection
- Background Jobs
- Program Errors
- White Spaces
- Batch Mode
- Defensive Programming and Error Messages
- Pipe
更详细的要求就看作业说明了
那就一样一样来,先写出最基本的Shell部分
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_BUFFER_SIZE 100
#define SHELL_NAME "jxtxzzw_Shell > "
int main(){
while (1){
showPrompt(SHELL_NAME); // 输出一些信息
char* buf = (char*)malloc(sizeof(char)*MAX_BUFFER_SIZE); // 创建最大的缓冲区用以读入
memset(buf,0,MAX_BUFFER_SIZE); // 清空了内存
fgets(buf,MAX_BUFFER_SIZE,stdin); // 读入命令
parse_token(buf); // 解析命令
if (feof(stdin))
exit(0); // 退出
updateHistory(); // 记录命令的历史记录
doSomething(); // 执行命令
}
return 0;
}
看样子还挺好
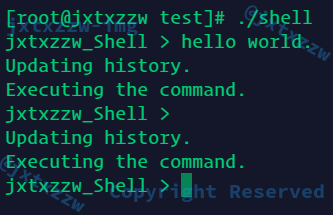
然后尝试执行简单命令,例如ls
尝试直接执行ls,不带参数
void doSomething(char* cmd) {
char* param[] = {};
printf("Executing %s...\n", cmd);
execvp(cmd, param);
printf("Executed.\n");
return;
}
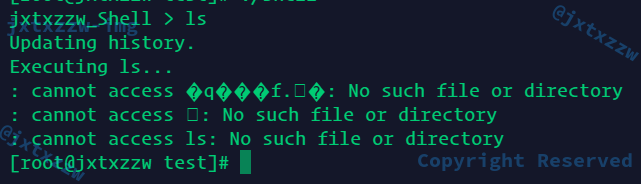
发现正常执行结束,但是并没有输出什么东西
这时候仔细检查一下输出的东西,发现
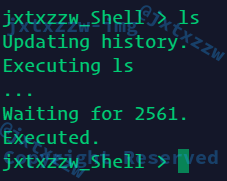
输出的cmd带了换行符
是读入的时候,带了一个\n,那么对于ls\n,自然是找不到这个命令的,因为只有ls这个命令
所以要去掉\n
可以使用strtok(cmd, "\n")命令,在cmd中找到第一个\n之前的部分,作为需要执行的命令
至于之后如何带着参数运行,就是后面解析器做的事了,现在只考虑执行最简单的命令
命令解析正确,但是没有输出任何东西
这里是因为我弄错一件事情,我给的参数是空串,其实看一下函数签名,需要的是一个字符串数组
尝试做如下修改
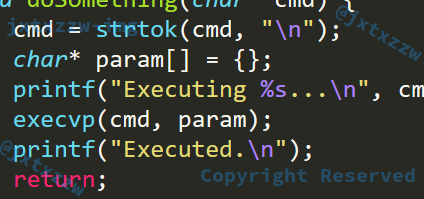
这是因为argv[]数组必须以NULL作为最后一个参数
继续修改
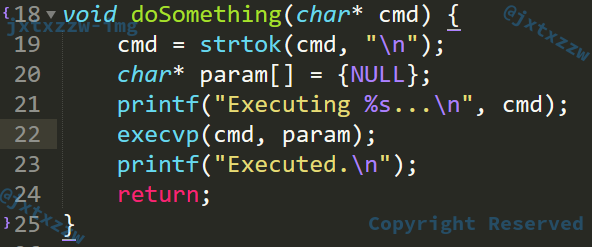
后来研究了一下是参数列表的第一个参数仍旧需要包含命令名称
- 第一个参数是命令名
- 第二个参数由命令名和传递给命令自身的参数组成,并且它必须以
NULL结束- 它将当前进程的映像交换为被执行的命令的映像
void doSomething(char* cmd) {
cmd = strtok(cmd, "\n");
char* param[] = {cmd,NULL};
printf("Executing %s...\n", cmd);
execvp(cmd, param);
printf("Executed.\n");
return;
}
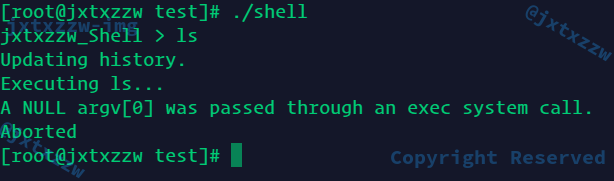
输出了正确结果
但是!程序结束了
这时候就要研究一下Linux的运行程序的机制了,C有没有什么系统调用是可以完成执行进程的
exec()函数簇包括$7$个和执行程序有关的函数,主要区别在于执行是按文件名还是路径名,传递参数的方式等
execve()的环境变量参数env恒为0,没有使用的必要了
execvp()能够直接执行ls这样的命令而不用加上路径,更接近于Shell,于是选择execvp()int execvp(const char *file ,char * const argv []); // execvp()会从PATH 环境变量所指的目录中查找符合参数file的文件名,找到后便执行该文件,然后将第二个参数argv传给该欲执行的文件。
execvp()能够执行一个新程序,但是需要注意的是,程序执行完新的程序没有能力返回到原先的程序
原因在于execvp()函数将新程序载入当前进程,并替换了当前进程的代码和数据,也就是说新程序开始后,原程序就自动被清除了
fork()函数是Unix的系统调用,调用fork()函数能够复制调用该函数的进程
复制产生新的进程后,再调用execvp()函数,这样就能既保存Shell程序,又能执行新程序
fork()函数很特殊的地方在于一次调用会产生两个返回值,父进程返回值为子进程的ID,子进程返回值为$0$,能够通过判断返回值来决定进程是执行新程序还是等待子程序结束
如果只使用fork()和execvp()函数,Shell程序不会等待子程序结束,而会自顾自地继续主循环,为了等待子进程的结束,我们要使用系统的wait()函数
调用wait()或者waitpid()函数后:
- 如果所有子进程都还在运行,则阻塞
- 如果一个子进程已经终止,正等待父进程获取其终止状态,则获取子进程终止状态并立即返回
- 如果没有子进程则立即出错返回
这时候就需要做两件事
- 用
fork()、wait()来修改执行命令的部分 - 完成命令的解析,处理好命令名称以及参数列表
首先用fork()和wait()命令修改doSomething()的框架
void doSomething(char* cmd) {
cmd = strtok(cmd, "\n");
param = {cmd, NULL};
printf("Executing %s...\n", cmd);
int pid;
if ((pid = fork()) < 0){ // fork()一个进程,获取pid
perror("Fork Error!\n"); // pid小于0,说明fork()出错,输出stderr信息
} else if (pid == 0){
execvp(cmd, parm); // pid等于0,这是一个子进程,执行命令
} else {
// pid不为0,说明这是父进程,fork()返回值是子进程的pid
printf("Waiting for %d.\n", pid);
int wait_ret = wait(NULL); // 等待子进程执行完毕
printf("Done waiting, and return value is %d\n", wait_ret);
}
printf("Executed.\n");
return;
}
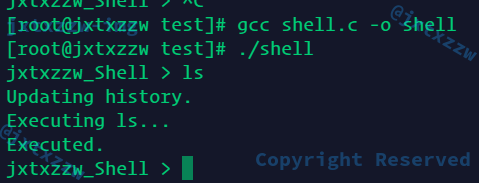
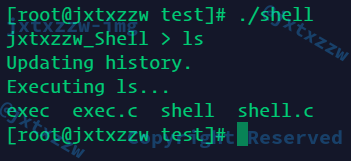
再次尝试运行ls,正常执行结果,且Shell没有结束,继续等待命令,然后继续执行也是正确的结果
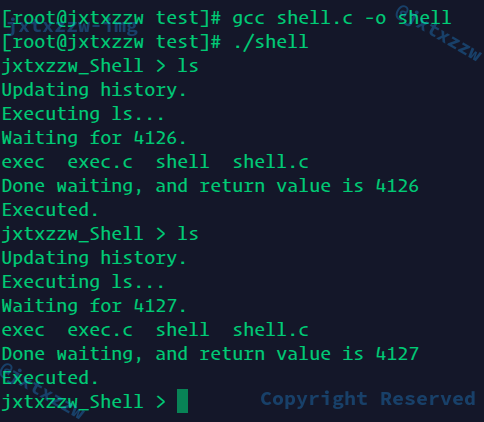
但是这里有一个比较麻烦的事情
或者说是潜在的BUG
那就是,ls、pwd等都是OK的
这些应用程序都是在bin目录下,而bin目录就是默认一定包括在PATH环境变量中的
所以执行这些命令,就会去PATH下找,然后找到bin下面的ls这些命令,然后执行
但是cd不行,比较特殊
看一下具体的说明
cddoes not exist as an executable command. (And it cannot, because a process can only change the working directory of itself, not of its parent.) You will need to implementcdyourself as a builtin, using thechdir()system call, similar to the way you’ve already implementedquit.
也就是说,出于安全考虑,cd只能由开发者自己实现成一个内建命令
特殊处理cd,来执行改变目录
当然如果要支持cd ~或者cd -就必须记录更多的信息,或者先系统调用得到对应的变量值,再执行cd PATH来改变目录
这就涉及到带参数的命令了,后面再实现
现在考虑怎么给命令带参数
命令读入一定是字符串,但是带着字符串做事情总归是一个累赘,所以最好有什么办法可以把命令解析以后的信息保留下来
我想到的是结构体
结构体保留了当前的命令名称、命令参数列表
如果有重定向的话,结构体还可以记录重定向的文件信息,否则可以给默认的值(stdin、stdout)
管道就是递归,可以考虑链表挂下去一个结构体,或者其他的结构等
typedef struct command
{
char* name; // 命令名称
char* argv[]; // 参数数组
int input_file_description; // 输入文件,默认是STDIN,如果需要重定向直接给文件描述符即可
int outpuut_file_description; // 输出文件,默认是STDOUT,如果需要重定向直接给文件描述符即可
int output_type; // 标记输出类型,即 > 还是 >>
struct command* next; // 下一条指令,可以用来执行管道
} COMMAND;
至于管道的时候,怎么把前一个输出的内容传递到下一个命令的输入,这个等后面遇到具体问题再实现
那么下面就要实现解析函数了
COMMAND* parse_token(char* buf){
COMMAND* cmd = (COMMAND*)malloc(sizeof(COMMAND)); // 保存命令的结构体
buf = strtok(buf, "\n"); // 先去掉换行符
char* token;
token = strtok(buf, " "); // 按空格分隔,取出第一个字符串,作为命令名
cmd->name = (char*)malloc(sizeof(char)*strlen(token));
strcpy(cmd->name, token); // 保存命令名
cmd->input_file_description = 0;
cmd->outpuut_file_description = 0;
cmd->output_type = 0;
cmd->next = NULL;
cmd->argv = (char**)malloc(sizeof (char*)*(MAX_ARGS)); // 参数列表
int index = 0;
while (token != NULL){ // 循环,以空格分隔,加入到argv[]数组
printf("%s\n",token);
cmd->argv[index] = (char*)malloc(sizeof(char)*strlen(token));
strcpy(cmd->argv[index], token);
index++;
token = strtok(NULL, " "); // 特别注意:循环取子串的时候,前一个参数为<code>{{EJS0}}</code>
}
cmd->argv[index] = NULL; // 最后一个是NULL
return cmd;
}
修改doSomething(),这样就可以解决解析的问题,可以实现解析命令了

之后传入参数尝试
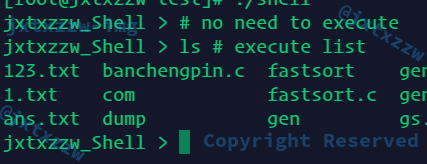
ls执行正确,执行后回到Shell,ls -l执行正确,ls -l -a执行正确
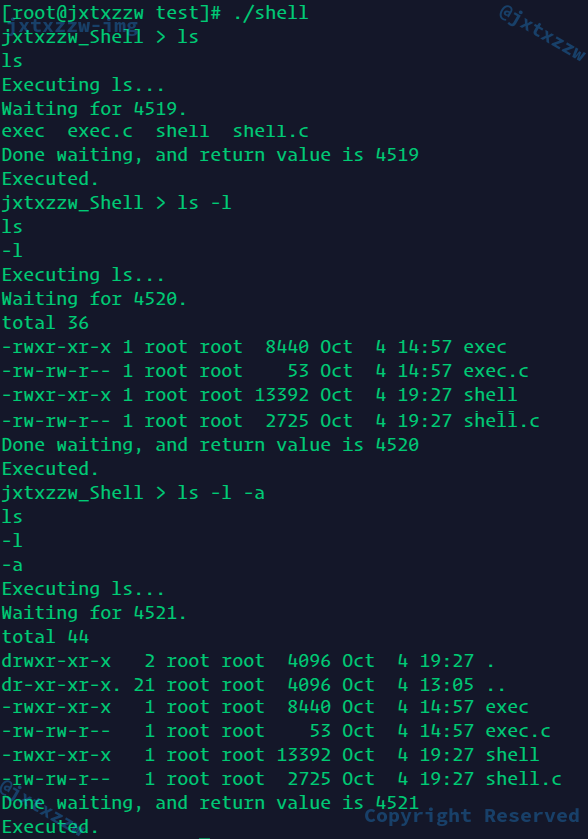
然后就可以尝试实现重定向
就是在解析字符串的时候判断<、>、>>等
然后拿着判断出来的信息,直接open,把文件描述符保存到结构体中
cmd->input_file_description = STDIN_FILENO; cmd->output_file_description = STDOUT_FILENO;
while (token != NULL){ // 循环,以空格分隔,加入到argv[]数组
// 解析文件重定向的部分
if (strcmp(token,"<")==0){ // 重定向输入
token = strtok(NULL, " "); // 获取文件名
fd = open(token, O_RDONLY); // 只读打开文件,并获得文件描述符
cmd->input_file_description = fd;
token = strtok(NULL, " "); //跳过文件名
continue; // 继续后面的解析
}
if (strcmp(token,">")==0){
cmd->output_type = 0; // 重定向输出
token = strtok(NULL, " "); // 获取文件名
fd = open(token, O_WRONLY|O_CREAT|O_TRUNC, S_IRWXU); // 只写方式打开文件,若文件不存在则创建,若已存在则TRUNC方式打开文件,并获得文件描述符
cmd->output_file_description = fd;
token = strtok(NULL, " ");
continue;
}
if (strcmp(token,">>")==0){
cmd->output_type = 1; // 重定向追加输出
token = strtok(NULL, " "); // 获取文件名
fd = open(token, O_WRONLY|O_CREAT|O_APPEND, S_IRWXU); // 只写方式打开文件,若文件不存在则创建,若已存在则APPEND方式打开文件,并获得文件描述符
cmd->output_file_description = fd;
token = strtok(NULL, " ");
continue;
}
cmd->argv[index] = (char*)malloc(sizeof(char)*strlen(token));
strcpy(cmd->argv[index], token);
index++;
token = strtok(NULL, " "); // 特别注意:循环取子串的时候,前一个参数为<code>{{EJS1}}</code>
}
然后在执行命令的部分,pid==0那里,就要做文件重定向了
else if (pid == 0){
int stdin_copy_fd = STDIN_FILENO;
int stdout_copy_fd = STDOUT_FILENO;
// 如果输入需要重定向,即输入文件描述符不为STDIN_FILENO
if (cmd->input_file_description != STDIN_FILENO){
stdin_copy_fd = dup(STDIN_FILENO); // 复制一份原来输入的文件描述符
dup2(cmd->input_file_description, STDIN_FILENO); // 重定向
}
// 如果输出需要重定向
if (cmd->output_file_description != STDOUT_FILENO){
stdout_copy_fd = dup(STDOUT_FILENO);
dup2(cmd->output_file_description, STDOUT_FILENO);
}
execvp(cmd->name, cmd->argv); // pid等于0,这是一个子进程,执行命令
fflush(stdout); // 重定向输出以后一定一定要flush一下
// 如果进行了重定向,恢复
if (cmd->input_file_description != STDIN_FILENO)
dup2(stdin_copy_fd, STDIN_FILENO);
if (cmd->output_file_description != STDOUT_FILENO)
dup2(stdout_copy_fd, STDOUT_FILENO);
}
下面到了激动人心的时刻了
普通命令执行成功
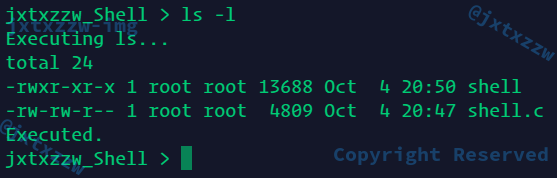
带参数命令执行成功
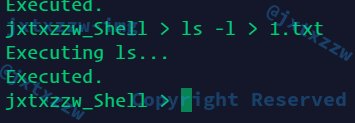
输出重定向成功,屏幕没有输出东西了,那么信息应该被输出到了文件中,这个等一下验证
但是可以看到,执行这句命令前Executing ls...被输出到屏幕了,执行这句命令以后Executed.也被输出到屏幕了,所以重定向之后的恢复功能也是正常的
下面检查一下是不是真的把ls -l的内容输出到了文件
可以尝试直接在Bash下执行
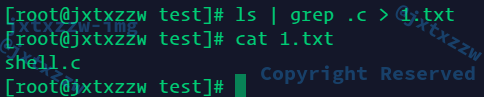
cat 1.txt
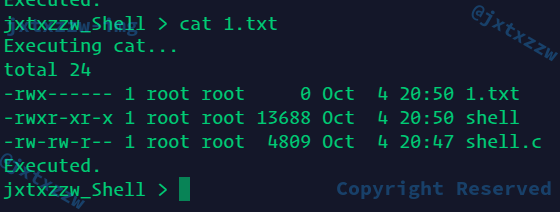
这与直接用cat命令查看的是一样的
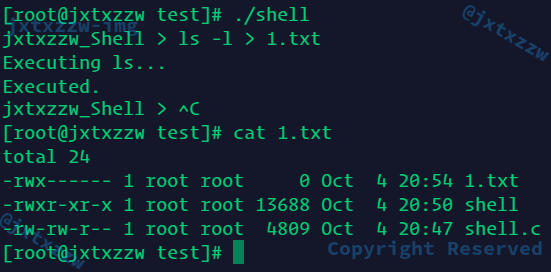
至于重定向出来的文件到底算不算要被ls,也就是ls -l需不需要把刚刚重定向创建的这个文件算进去,我特意做了测试
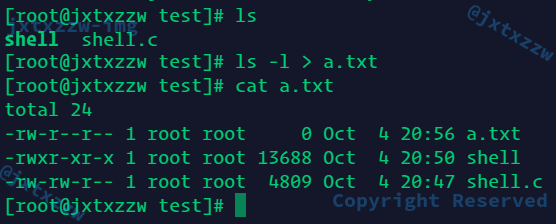
所以我的实现是没有问题的
下面尝试输入重定向
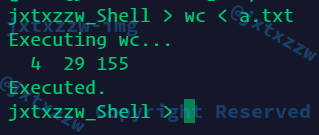
尝试输入重定向以后重定向输出
也就是先把a.txt交给wc执行,然后执行结果输出到b.txt,看看既有输入又有输出是不是正确
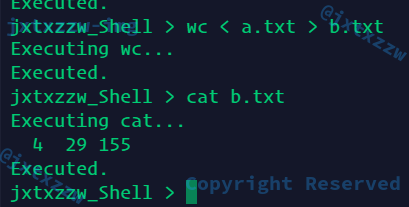
也是正确的
看看追加
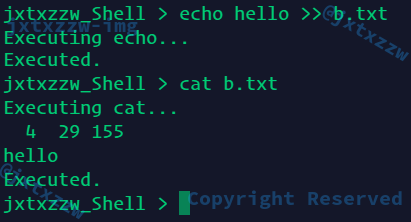
也是正确的
接下来就要处理一些非法的重定向
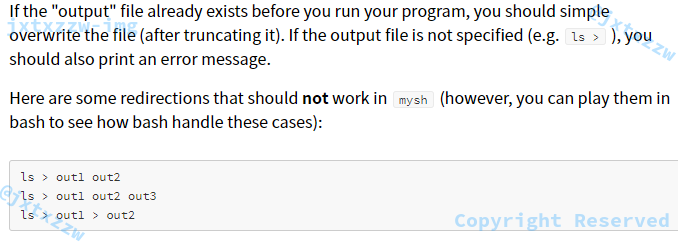
看看Bash怎么处理ls > 1.txt > 2.txt的
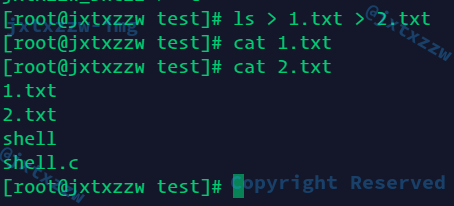
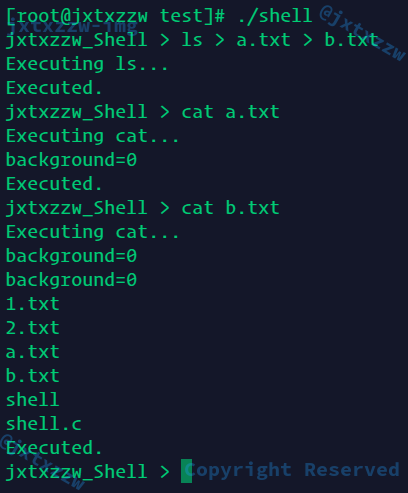
我和Bash做的一样,所以我认为这种写法不算是需要异常处理的,就可以认为是正确的
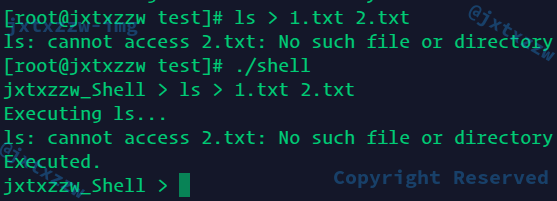
这个我也和Bash的处理是一样的,就直接让ls抛出异常了,就不需要由我特判了
所以只需要特判ls >这种情况
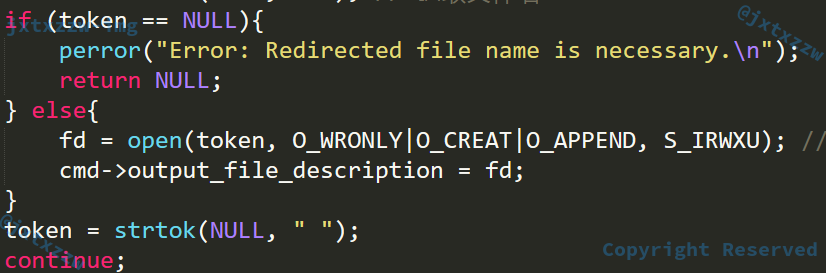
太棒了,那就完成了基本上很多功能了
错误信息的处理,等到全部完成以后一次性检查和实现,一些多余输出信息,也等到那时候再处理,现在还是需要保留这些信息以便调试
因为管道有点难,那么接下来在实现管道之前,把那个内建命令cd给实现了
需要指出的是,除了cd,还有很多命令也是需要手动实现的,是不可以execvp()执行的
Other commands you will need to implement as builtins as well, if you plan to implement them, include (for example, I’m not trying to be thorough):
pushdandpopdexit,logout,bye, etcfg,bg,jobs, and the&suffixhistoryset,unset,export
由于基本类似,就是自己写代码实现,也不需要高级的数据结构,只要把逻辑理清楚,代码还是很简单的
例如,pushd和popd就是相当于手动实现一个栈,history就相当于实现一个队列……
我就只实现cd了,毕竟全部都实现一次也不现实
cd的主要部分:
cd返回用户家目录cd ~返回用户家目录cd PATH改变到指定目录cd -返回上一次目录cd ~USERNAME改变到指定用户的家目录
最难的部分没有要求实现,即无需支持cd ~USERNAME来定位到制定用户的家目录,只要直接报错就可以了,这就给我们的设计带来了极大的方便
You do not have to support tilde (~). Although in a typical Unix shell you could go to a user’s directory by typing “cd ~username”, in this project you do not have to deal with tilde. You should treat it like a common character, i.e. you should just pass the whole word (e.g. “~username”) to
chdir(), and chdir will return error.
比较关键的问题有$2$个,我怎么知道用户家目录是什么,以及,我怎么知道用户上一次目录在哪里
至于PATH,反正是命令行参数,总归是有办法传进去的
这两个问题的解决方案,就是去翻环境变量
用户的家目录定义在$HOME,用户上一次的目录定义在$OLDPWD
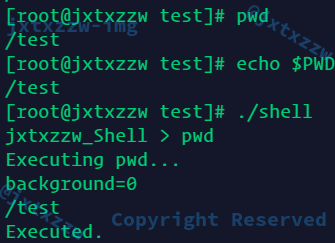
测试一下,cd和cd ~都正确
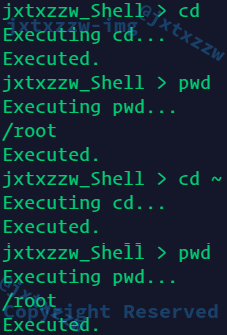
cd -正确
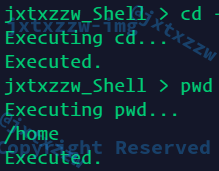
cd PATH正确
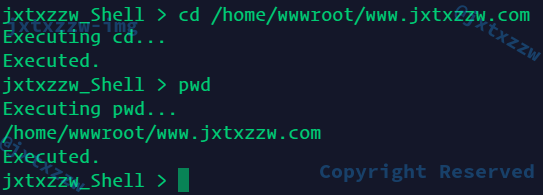
其他的内建命令也是正确的
还有一个后台运行的事情
这个比较简单,只要看存在&,就不再对后台进程进行wait
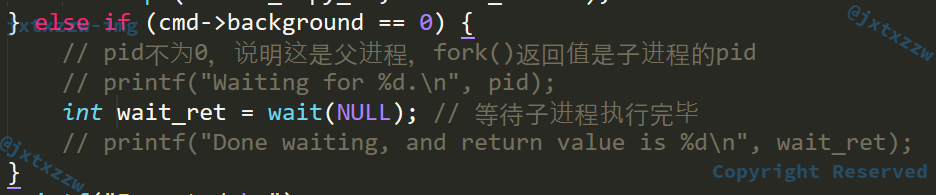
测试,发现效果不太好
再改
//杀死父进程,后台进行
if(cmd->background == 1 && pid != 0){
printf("[process id %d]\n",pid);
return;
}
//父进程等待子进程
if(waitpid(pid,NULL,0) == -1){
printf("wait for child process error!\n");
}
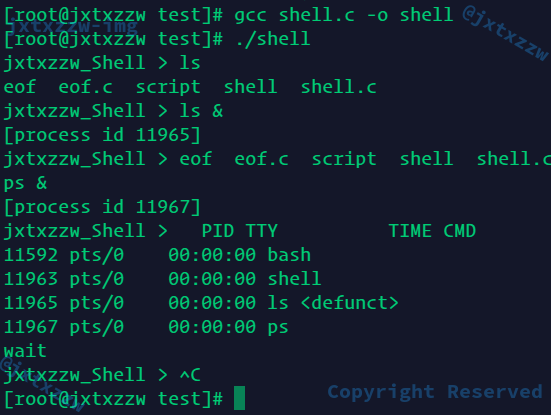
可以看到,运行ls,正常得到结果,后台运行ls &,先是输出了[1] 10376,然后返回了运行结果
运行结果和Shell的提示信息交杂了
这是因为没有机制可以保证子进程和父进程谁先返回
这是不可避免的,就连Bash都没有处理,那我自己写的Shell就随他去吧
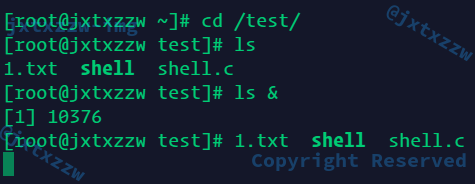
反正继续运行是OK的
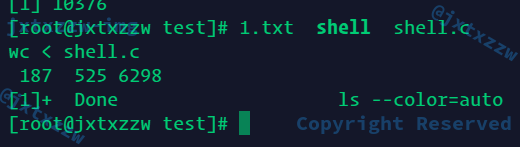
我自己实现的Shell也完全这样的

然后说到wait的这个事情
先看看Bash怎么做的
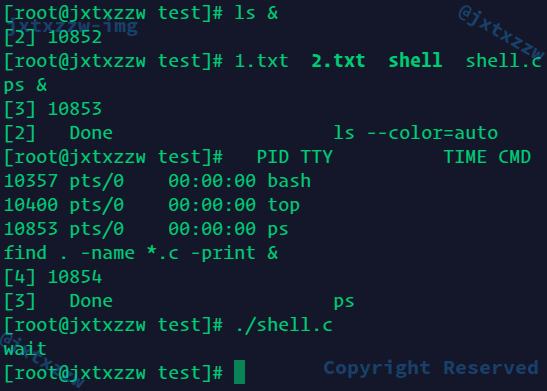
依次后台执行,但是因为输出的信息顺序是没有可能确定的,就显得有些混乱
但是最后wait命令输完,等待全部结束(确实早就结束了),然后返回,之后就正常了
然后看一下我自己的程序能不能完成这个任务
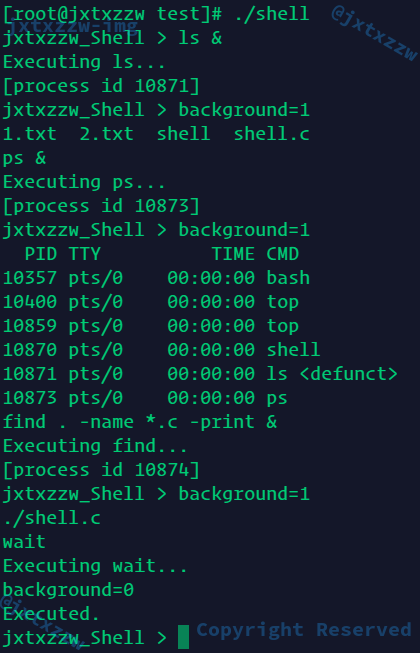
依次输出了Executing...等信息,background=1,然后等我输入wait以后,等待子进程执行完毕,然后输出Executed
好像没什么事
但是遇到top命令的时候
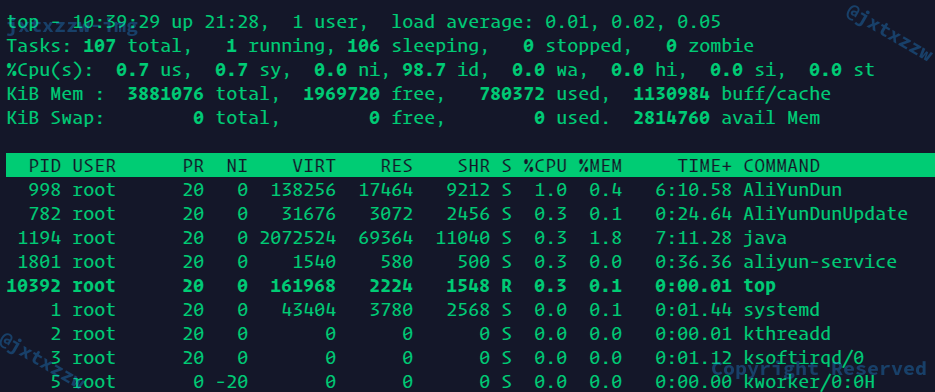
全屏输出了信息
按q退出
后台运行top &,没有输出信息,只输出了PID
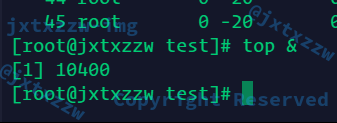
我自己的Shell会发生什么情况
执行top
正常全屏输出
按q退出,发现输出了Executed.说明确实完成了命令的执行
执行top &,却也全屏输出了
而且这时候按q没有反应
这应该是中断处理上面的事情了
例如,对于top命令,特判了不显示,且特殊处理了终端信号SIGQUIT、SIGSTOP等
注意,对于后台运行的子进程,如果父进程提前退出了,自然会成为init进程的孩子;而如果这些子进程在父进程退出前退出,又没有对应的waitpid()进行回收,就会成为僵尸进程。使用signal()处理SIGCHLD可以解决这个问题,并且由于Linux的信号是不排队的,需要将所有的已结束的子进程进行回收。
但是,仅仅增加一个信号处理函数,对于前台运行的进程,waitpid()阻塞过程是否会失效?为了让这两种waitpid()不相互干扰,把后台运行进程的pid放入一个专门的数组中,信号处理函数只对这一类进程进行处理。对于不是后台运行的子进程,在信号处理函数什么也不做就返回后,使用指定了其pid的waitpid()处理。
中断不做
反正作业没要求
但是exit还是要做的
这个简单,判断命令是exit就直接返回退出
其他地方都不用改,只加一句话
if (strcmp(cmd->name, "exit") == 0)
exit(0);
另外,我认为exit > 1.txt是没有意义的,所以我处理的时候,只要命令名称是exit,则无视后面的内容,哪怕后面是重定向甚至非法格式,我都会执行退出
strcpy(cmd->name, token); // 保存命令名
if (strcmp(cmd->name, "exit") == 0)
return cmd;
在异常处理这一块,作业简化了很多要求
简单说,就是任何与程序相关的错误,例如ls参数错误,都由程序打印他自己特定的错误信息,不论是输出到标准输出还是标准错误输出
我们只需要负责处理Shell语法和一些内建操作的错误
而且打印的错误也不需要对每个错误都进行处理
只需要输出一样的信息
char error_message[30] = "An error has occurred\n"; write(STDERR_FILENO, error_message, strlen(error_message));
那就很简单了
把原来的perror全部替换成上面这句就行了
测试一下,发现输出错误信息都是符合要求的,顺便测试了exit
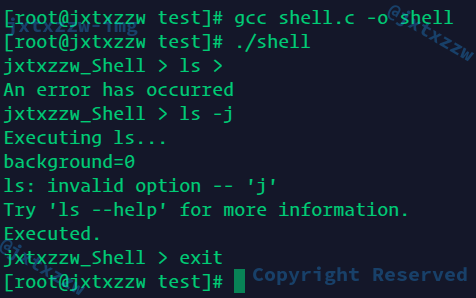
还要支持空格

前两个肯定是没问题的
因为我做的就是按照空格分词
现在要支持第三个
那就要修改parse_token()了
方案很多,例如可以先对命令用>分词,因为重定向输入输出只能最多有一个
然后>前面的肯定就是命令,后面的就肯定是文件
但是,这也会有潜在的问题
因为这样分词对于正确的命令来说肯定还是对的
但是万一有输错误的命令呢
譬如上面说的ls>1.txt>2.txt,那取出>以后,再去解析后面的东西是非常麻烦的
甚至,对于完全正确的命令wc<1.txt>>2.txt,即从1.txt统计wc的内容追加到2.txt,这个解析会很难受
所以我的方案是,对于读入的字符串,先遍历一遍,规格化,改加空格的加上,然后在做事情
这样我就只需要在前面加一个函数,不需要修改目前已有的任何代码
甚至后面如果需要支持管道左右没有空格的时候,我也只需要在规格化这个函数里面加一些代码,不需要大改原来的解析函数
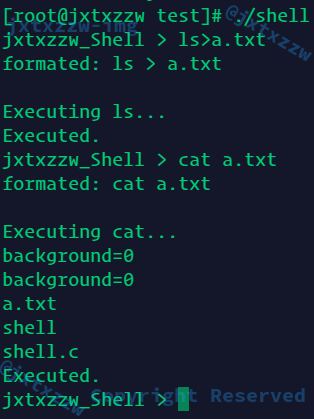
char* formated(char* buf)
{
char* formated_buf = (char*)malloc(sizeof(char)*MAX_BUFFER_SIZE); // 创建最大的缓冲区用以读入
int i = 0;
int j = 0;
int len = strlen(buf);
while (j!=len){
if (buf[j]!='>' && buf[j]!='<'){
// 不是重定向符,照抄
formated_buf[i++] = buf[j++];
} else if (buf[j]=='<' || buf[j] == '>'){
formated_buf[i++] = ' '; // 不管原来有没有空格,都加上空格,反正多个空格是可以解析的
formated_buf[i++] = buf[j++];
// 处理掉>>
if (buf[j-1]=='>' && buf[j]=='>'){
formated_buf[i++] = buf[j++];
}
formated_buf[i++] = ' ';
}
}
printf("formated: %s\n", formated_buf);
return formated_buf;
}
另外还有一个,在Bash里面什么都不输入就直接回车,或者输入一些空格以后回车,是会继续回到Prompt的
接下来进行批处理
这个好像还挺关键的
因为作业说,要自动评分,会大量使用批处理模式
然后还说,会提供批处理脚本以供测试(我也没见你在哪里提供了这玩意)

那就自己写了再说
实现其实说起来很简单
如果没有命令行参数,那就和上面一样进入交互模式
如果带了命令行参数,就打开文件,进行批处理模式
所谓批处理模式,就是一次读一行,然后读入的字符串还是按照上面的方法执行
批处理模式下,为了方便测试,应该把读入的命令在执行之前先显示出来,并且要注意批处理脚本不存在的时候的错误信息
int main(int argc, const char* argv[]){
FILE* in = NULL;
if (argc == 1){
in = stdin;
} else if (argc == 2){
in = fopen(argv[1], "r");
}
if (in == NULL){
write(STDERR_FILENO, error_message, strlen(error_message));
exit(-1);
}
if (in != stdin)
write(STDOUT_FILENO, buf, strlen(buf)); // 如果在批处理模式,则在执行之前先输出当前需要执行的命令
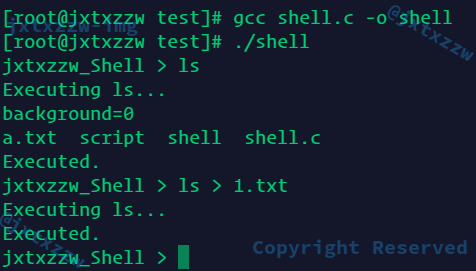
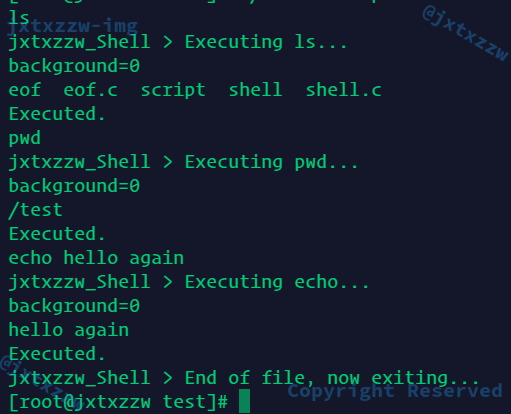
交互模式正确
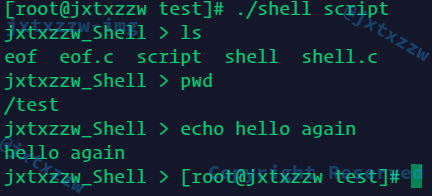
测试批处理模式,例如在一个文件中写入
ls ls -l pwd
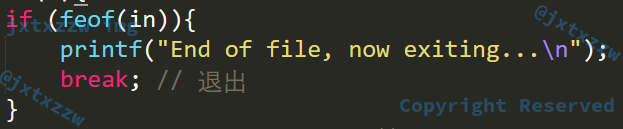
差点出事
因为没写exit,也没有做EOF判断
补上
现在执行
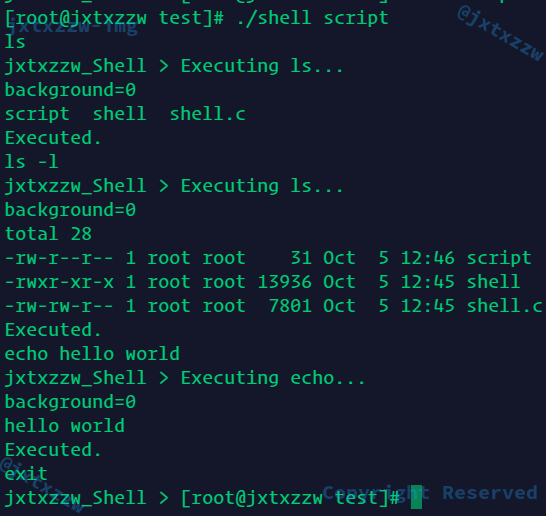
正确
不带exit也没事
下面把所有调试部分的printf()都给注释掉
其他的printf()换成write()
有些需要带%s的字符串,可以先用sprintf()输出到char*,然后借用showPrompt()输出
输出的格式也美观了很多

说自动化评分,要注意错误信息的处理

对于我自己的Shell的错误命令行参数个数,输出错误信息,需要优雅地退出


这种情况需要输出错误信息,但是要继续
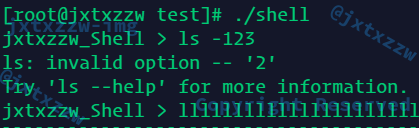
继续了

也继续了

这个早在前面就解决了
现在所有功能都实现了
可以说是完工了
后面还很贴心给了很多提(废)示(话)
Redirection is relatively easy to implement: just use
close()on stdout and thenopen()on a file. You can also usedup2()system call which is safe for concurrency.Beat up your own code! You are the best (and in this case, the only) tester of this code. Throw lots of junk at it and make sure the shell behaves well. Good code comes through testing — you must run all sorts of different tests to make sure things work as desired. Don’t be gentle — other users certainly won’t be. Break it now so we don’t have to break it later.
……
下面就是奖金任务了——管道
实现管道,其实就是递归
例如可以遍历一遍,找到第一个|,这之前的命令取出来做parse_token()并执行,后面的继续递归
或者,也可以一次性全部解析完,把所有的命令依次解析以后挂到cmd->next链表
不过,比较麻烦的是,管道是要把前一次的输出传递过来的,这个比较难处理
而且,管道和重定向同时存在的话……递归都不好做啊
先搞一个字符串分隔的东西出来
while ((cursor=strchr(formated_buf,'|'))!=NULL){
char* formated_buf_a = formated_buf;
char* formated_buf_b = cursor + 1;
*cursor = '\0';
printf("%s, %s\n", formated_buf_a, formated_buf_b);
// int pipe_fd[2];
// pipe(pipe_fd);
// pid_t child1, child2;
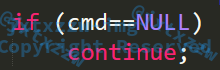
cmd = parse_token(formated_buf); // 解析命令
if (cmd==NULL)
continue;
doSomething(cmd);
formated_buf = formated_buf_b;
}
if (formated_buf!=NULL){
cmd = parse_token(formated_buf); // 解析命令
if (cmd==NULL)
continue;
doSomething(cmd);
formated_buf = formated_buf_b;
}
这一段做的就是,不断地取出|之前的部分,执行,执行以后循环地执行后面一半的解析,直到为空
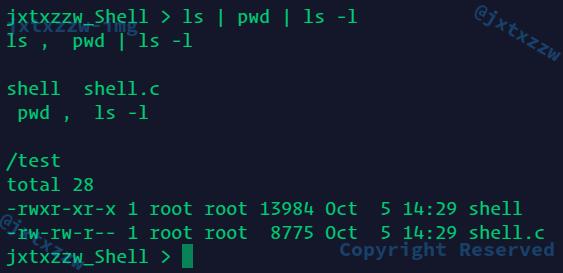
如图,ls | pwd | ls -l首先取出ls执行,得到结果,然后对pwd | ls -l解析,取出pwd,执行得到结果,最后运行ls -l得到结果,然后停止
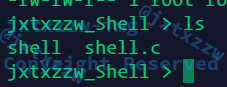
并且不带管道也没事,可以很正常的运行,不会有什么空指针异常
命令是能执行了,但是有一个比较致命的问题没有解决,那就是,管道是要求前一个输出作为后一个的输入的
直接用pipe()手糊一个
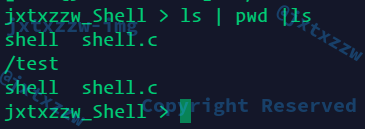
看到原来的是三个命令分别按顺序执行,但是都输出了
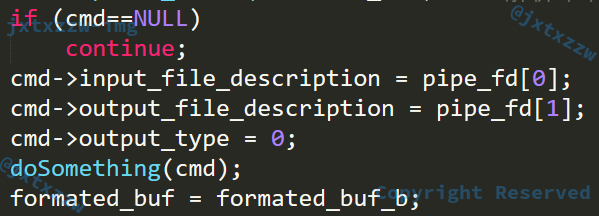
修改以后,只输出了最后一个
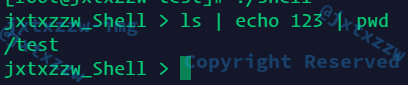
至于是只执行了最后一个,还是其实前面输出传递过去了,就要grep等来测试
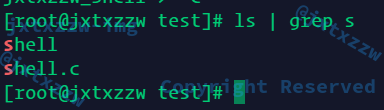
好像并没有什么东西传递过去
最后一个命令我忘记写了
if (formated_buf!=NULL){
cmd = parse_token(formated_buf); // 解析命令
if (cmd==NULL)
continue;
if (piped == 1){
cmd->input_file_description = pipe_fd[0];
cmd->output_file_description = STDOUT_FILENO;
cmd->output_type = 0;
}
doSomething(cmd);
}
可以看到说文件描述符不对
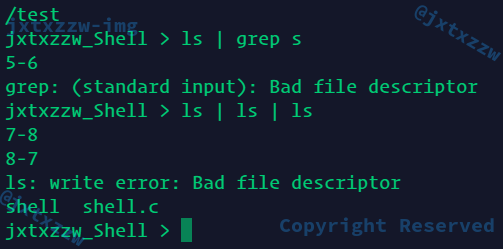
稍作修改,就OK了
在while退出以后,只剩下一个命令
这个命令需要判断是到底是pipe的最后一个命令,还是没有pipe就只是一个命令
如果是原始的一个命令
该怎么做还是怎么做
如果是pipe的最后一个,那么要重定向输入输出
输入就是fd[0],但是输出要回到标准输出
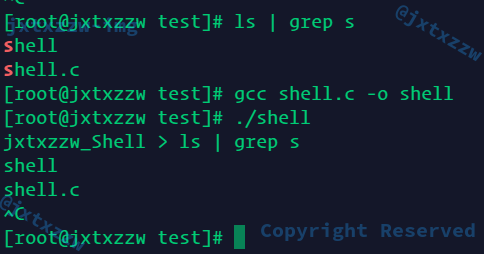
这时候ls的输出已经正常交给grep了,然后grep得到结果
但是一个是关键字没有变色
这个不是我们能解决的问题
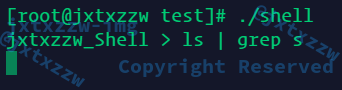
另外有一个小问题,就是输出了以后,还在等着输入
就像是一直在等待用户输入一样,没有一个EOF传过去
如上图,输出了shell shell.c以后,还等着输入,结束不了,只能强制退出
这是因为,管道是单独构成一种独立的文件系统
管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在于内存中
管道两端可分别用描述字
fd[0]以及fd[1]来描述需要注意的是,管道的两端是固定了任务的。即一端只能用于读,由描述字
fd[0]表示,称其为管道读端;另一端则只能用于写,由描述字fd[1]来表示,称其为管道写端。如果试图从管道写端读取数据,或者向管道读端写入数据都将导致错误发生。一般文件的I/O函数都可以用于管道,如close、read、write等如果管道的写端不存在,则认为已经读到了数据的末尾,读函数返回的读出字节数为$0$
当管道的写端存在时,如果请求的字节数目大于PIPE_BUF,则返回管道中现有的数据字节数,如果请求的字节数目不大于PIPE_BUF,则返回管道中现有数据字节数(此时,管道中数据量小于请求的数据量);或者返回请求的字节数(此时,管道中数据量不小于请求的数据量)
因此,要及时关闭管道的写端,以便管道能读到EOF
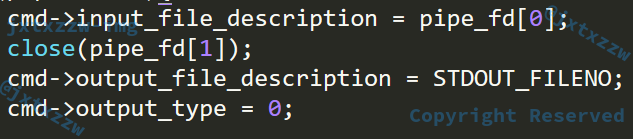
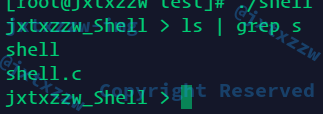
现在正常了
但是好像还有点问题,如果连续多个管道的话,开开关关也是非常麻烦的事情
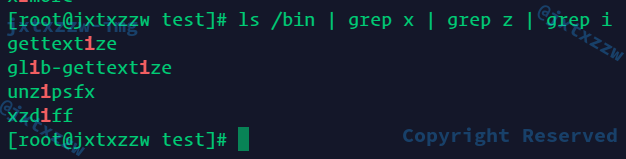

就一直在等待输入了
我一开始的处理方法是
结果遇到的问题是,例如我ls | grep s
输出包含s的东西
他输出了shell shell.c
但是最后输出了以后没回到大循环的地方
仿佛还在等输入
之后稍作修改改成了这个样子
稍微解决了一些小问题,但是关键问题还没能解决

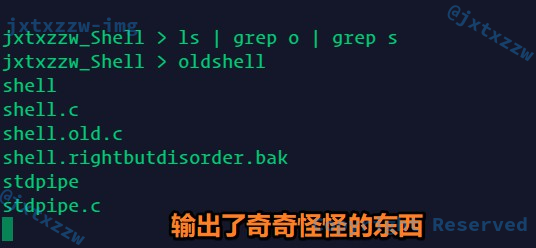
如图,运行
ls | grep s
以后,先输出了Prompt,然后才输出内容
导致后面可以正常运行命令,但是缺了提示
并且,多个管道嵌套的时候,输出的内容变得奇奇怪怪
这个地方我卡了很久很久
自己研究了两个半天
然后上机课上ybwu也一起过来看
他说我的逻辑是没有问题的
说是父进程和子进程的问题,是阻塞的问题
然后我测试了一下
我把waitpid(pid)换成了waitpid(pid, NULL, WNOHANG)
也就是,父进程发现子进程未完成的时候,无视,并继续
也就是说毫无意义
但是这样可以继续运行后面的命令,也就是说回到大循环了
waitpid(pid, NULL, 0)
父进程发现子进程未完成,阻塞
然后就输出东西以后狂按回车、输入东西,都没用
这样就似乎是说,死循环,或者是,子进程一直没有完成
但是当运行ls | pwd的时候,却又输出了pwd应该输出的东西
所以就很迷
ybwu看了很久很久也没有想出来到底怎么回事
ybwu就站在我电脑后面看我的代码,看看、思考、看看、思考………
交流的结果就是,ybwu说,我也不知道了,我看不出什么问题,你GDB进去调试吧
这里说一个GDB调试子进程的技巧
gcc -g shell.c -o shell gdb shell (gdb) set follow-fork-mode child (gdb) b 295 (gdb) run
可以选择性地跟踪子进程或者父进程
具体网搜
快下课的时候,ybwu说了一句
我想想我是怎么实现的……记不得了……反正我没有用这一堆
pipe,我只用了一个,你是不是这堆pipe弄的不对,你自己GDB调试吧,我不管你了
然后他就不见了
回来以后,我想了一下
然后网搜了递归实现的pipe
还翻出来了阳神的代码
递归是这样的
void mypipe() {
int fd[2];
switch (pid) {
case 0:
dup2(fd[1], STDOUT_FILENO);
close(fd[0]);
close(fd[1]);
if ()
mypipe();
else {
execvp();
}
break;
default:
dup2(fd[0], STDIN_FILENO);
close(fd[0]);
close(fd[1]);
while (wait(NULL) > 0);
execvp()
break;
}
}
其实这里也很难说是只用了一个pipe
一个pipe肯定是不能又读又写的
而且关掉了的pipe又不可能重新打开
所以其实这里用到了栈
也就是递归的时候其实是有很多副本的
每个副本局部变量新弄出来一个pipe_fd
所以其实也是用到了很多pipe
递归实在是太不优雅了
而且递归有爆栈的危险
所以我还是用循环
int pid;
for (cmd_index = 0;cmd_index < pipenumber; cmd_index++) {
int pid = fork();
if (pid < 0){
} else if (pid == 0){
} else {
}
}
这里一开始我还是用的之前的修改的
if (cmd_index == 0){
close(pipe_fd[pipe_index][0]);
dup2(pipe_fd[pipe_index][1], STDOUT_FILENO);
execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv);
perror("exec");
return -1;
} else if (cmd_index == pipenumber - 1){
dup2(pipe_fd[pipe_index][0], STDIN_FILENO);
close(pipe_fd[pipe_index][1]);
execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv);
perror("exec");
return -1;
} else {
close(pipe_fd[pipe_index][1]);
dup2(pipe_fd[pipe_index][0], STDIN_FILENO);
close(pipe_fd[pipe_index+1][0]);
dup2(pipe_fd[++pipe_index][1], STDOUT_FILENO);
execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv);
perror("exec");
return -1;
}
然后发现一个巨大的问题
我完全弄错了pipe这个神奇的东西
ybwu说pipe是一个神奇的东西,有文件描述符但不是文件
是内存里的,是用进程之间的通信来实现的
那所以其实应该是这样的
if (pid == 0) {
dup2(pipe_fd[pipe_index][1], STDOUT_FILENO);
execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv);
} else {
dup2(pipe_fd[pipe_index][0],STDIN_FILENO);
}
子进程重定向管道的写端到自己的标准输出,然后关掉管道的读、写
父进程重定向管道的读端到自己的标准输入,然后关掉管道的读、写
所以这样一来
fork以后,分叉
但是几乎同时地,父进程看着管道的读端有没有东西蹦出来、子进程一旦产生东西就往管道的写端写入
管道的写和读是通的,写端丢进去的就到了读端出来了
然后父进程输出到屏幕
所以,至此完成了
ls | grep s
之后要实现多个管道
如果不用递归,那就还是只能多开几个管道了
// 子进程做的事 dup2(pipe_fd[pipe_index][1], STDOUT_FILENO); close(pipe_fd[pipe_index][0]); close(pipe_fd[pipe_index][1]); execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv); // 父进程做的事 dup2(pipe_fd[pipe_index][0],STDIN_FILENO); dup2(pipe_fd[pipe_index+1][1],STDOUT_FILENO); close(pipe_fd[pipe_index][0]); close(pipe_fd[pipe_index][1]); waitpid(pid,NULL,0); pipe_index++;
注意,子进程只从管道写,但是父进程需要读了以后把输出送到下一层的管道
稍作几个测试
马上就会发现,有时候程序结束了,输出了新的Prompt,但是没有结果,或者,一直等待,或者……
然后就马上想到上面这段代码存在一个显而易见的问题
那就是,最后一个管道的输出不应该再往后面传了,而是应该输出到屏幕
不管是子进程还是父进程
所以,需要加入特判
// PID == 0 if (cmd_index != pipenumber - 1) dup2(pipe_fd[pipe_index][1], STDOUT_FILENO); else dup2(STDOUT_COPY, STDOUT_FILENO); // PID > 0 if (cmd_index != pipenumber-1) dup2(pipe_fd[pipe_index+1][1], STDOUT_FILENO); else dup2(STDOUT_COPY, STDOUT_FILENO);
当然,最后全部执行完,不忘恢复
close(pipe_fd[pipe_index][1]); close(pipe_fd[pipe_index][0]); dup2(STDIN_COPY, STDIN_FILENO); dup2(STDOUT_COPY, STDOUT_FILENO);
最后完整的pipe部分为
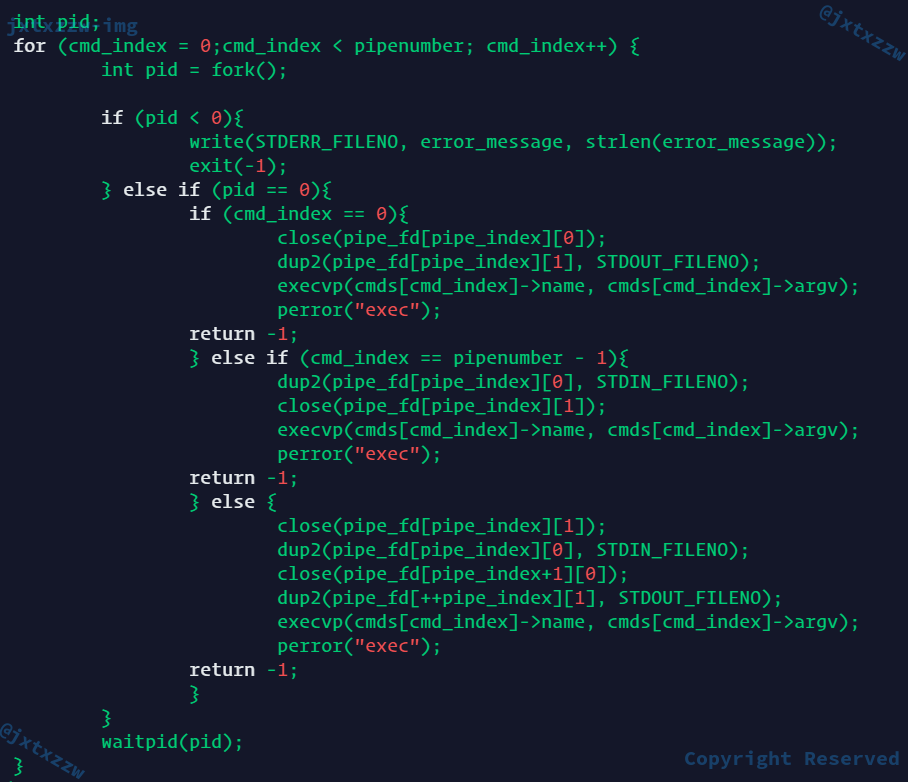
for (cmd_index = 0;cmd_index < pipenumber; cmd_index++) {
int pid = fork();
if (pid < 0){
write(STDERR_FILENO, error_message, strlen(error_message));
exit(-1);
} else if (pid == 0){
printf("cmdindex=%d\n",cmd_index);
if (cmd_index!=pipenumber-1)
dup2(pipe_fd[pipe_index][1], STDOUT_FILENO);
else
dup2(STDOUT_COPY,STDOUT_FILENO);
close(pipe_fd[pipe_index][0]);
close(pipe_fd[pipe_index][1]);
execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv);
perror("exec");
return -1;
} else {
// printf("pid=%d, cmd_index=%d\n",pid, cmd_index);
dup2(pipe_fd[pipe_index][0],STDIN_FILENO);
if (cmd_index!=pipenumber-1) dup2(pipe_fd[pipe_index+1][1],STDOUT_FILENO);
else dup2(STDOUT_COPY, STDOUT_FILENO);
close(pipe_fd[pipe_index][0]);
close(pipe_fd[pipe_index][1]);
waitpid(pid,NULL,0);
dup2(STDOUT_COPY, STDOUT_FILENO);
pipe_index++;
}
}
close(pipe_fd[pipe_index][1]);
close(pipe_fd[pipe_index][0]);
dup2(STDIN_COPY, STDIN_FILENO);
dup2(STDOUT_COPY, STDOUT_FILENO);
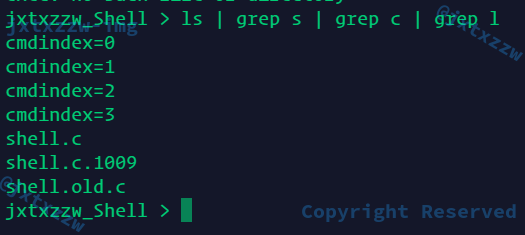
与Bash结果一致
连续执行也是没问题的

下面支持管道和重定向同时存在
这部分就比较简单了
输出重定向好办
if (cmd_index!=pipenumber-1) dup2(pipe_fd[pipe_index+1][1],STDOUT_FILENO);
else {
if (cmds[cmd_index]->output_file_description!=STDOUT_FILENO){
dup2(cmds[cmd_index]->output_file_description, STDOUT_FILENO);
} else {
dup2(STDOUT_COPY, STDOUT_FILENO);
}
}
逻辑上就是这么简单
如果命令有指定非标准输出的,那就重定向到那个文件,否则重定向回到屏幕
但是设计输入的时候就要考虑了

这样显然是行不通的
这时候就要考虑
到底管道里面的输入重定向可能出现在哪里
我觉得只能出现在第一个参数
中间出现都是无意义的
因为像sort,要么管道传过去XXX | sort,要么文件sort < XXX,不可能XXX | sort < YYY
类似的,输出重定向也只能是最后一个命令
否则就要报错
那就就改源代码
增加更多的特判
for (cmd_index = 0;cmd_index < pipenumber; cmd_index++) {
int pid = fork();
if (pid < 0){
write(STDERR_FILENO, error_message, strlen(error_message));
exit(-1);
} else if (pid == 0){
if (cmd_index != 0 && cmds[cmd_index]->input_file_description != STDIN_FILENO){
perror("invalid input redirection.\n");
exit(-1);
}
if (cmd_index == 0 && cmds[cmd_index]->input_file_description != STDIN_FILENO){
dup2(cmds[cmd_index]->input_file_description, STDIN_FILENO);
}
if (cmd_index != pipenumber-1)
dup2(pipe_fd[pipe_index][1], STDOUT_FILENO);
else {
if (cmds[cmd_index]->output_file_description != STDOUT_FILENO){
dup2(cmds[cmd_index]->output_file_description, STDOUT_FILENO);
} else {
dup2(STDOUT_COPY, STDOUT_FILENO);
}
}
close(pipe_fd[pipe_index][0]);
close(pipe_fd[pipe_index][1]);
execvp(cmds[cmd_index]->name, cmds[cmd_index]->argv);
perror("exec");
exit(-1);
} else {
dup2(pipe_fd[pipe_index][0],STDIN_FILENO);
if (cmd_index != pipenumber-1)
dup2(pipe_fd[pipe_index+1][1],STDOUT_FILENO);
else {
if (cmds[cmd_index]->output_file_description!=STDOUT_FILENO){
dup2(cmds[cmd_index]->output_file_description, STDOUT_FILENO);
} else {
dup2(STDOUT_COPY, STDOUT_FILENO);
}
}
close(pipe_fd[pipe_index][0]);
close(pipe_fd[pipe_index][1]);
waitpid(pid,NULL,0);
dup2(STDOUT_COPY, STDOUT_FILENO);
pipe_index++;
}
}
close(pipe_fd[pipe_index][1]);
close(pipe_fd[pipe_index][0]);
dup2(STDIN_COPY, STDIN_FILENO);
dup2(STDOUT_COPY, STDOUT_FILENO);
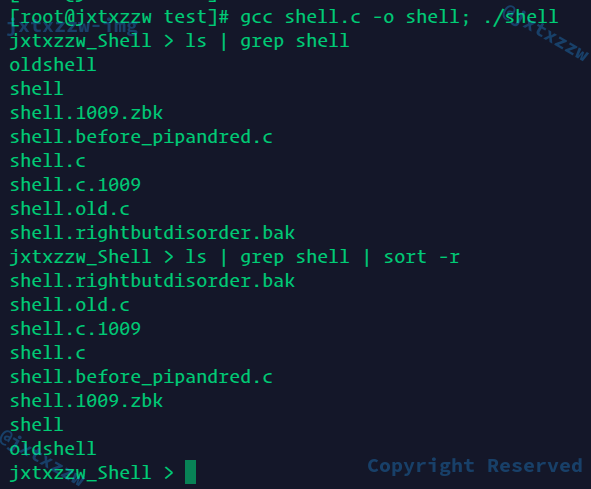
管道正常
多个管道正常
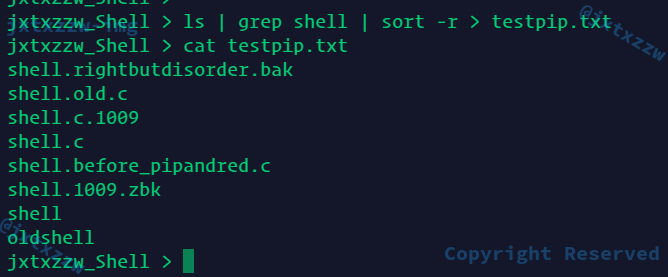
管道+输出重定向正常
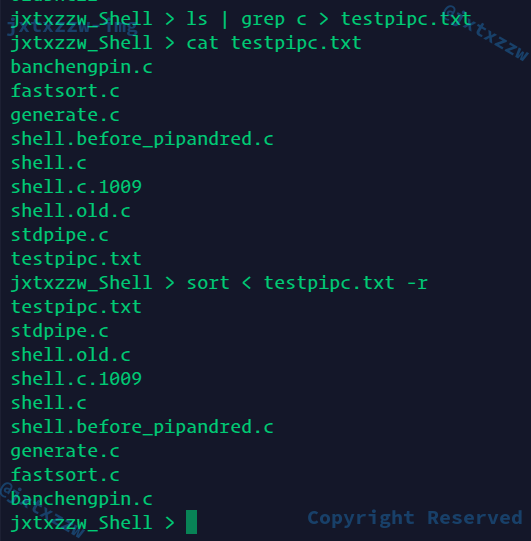
管道+输入重定向正常

管道+输入重定向+输出重定向正常
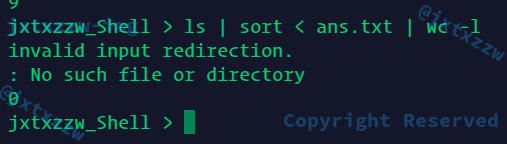
异常处理
然后修改formated()函数支持管道左右没有空格
只改动一个地方
while (j!=len){
if (buf[j] != '>' && buf[j] != '<' && buf[j] != '|'){
// 不是重定向符、不是管道,照抄
formated_buf[i++] = buf[j++];
} else if (buf[j]=='<' || buf[j] == '>' || buf[j] == '|'){

不管多奇葩的组合都是正确的
下面增加环境变量的解析
以及,另外还有一个问题,如果带了参数带了",是要把双引号之间的东西包括空格都放在一起作为一个参数的
下面就修改解析函数
首先来说说环境变量的解析
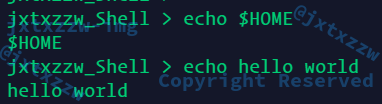
默认肯定是这样的

但是他应该是这样的
所以就要解析
char* envReplace(char* str){
char* ret;
if (str == NULL){
ret = NULL;
} else if (str[0]=='
之后只要token = envReplace(strtok(NULL, " "));但是,这也只能解决了类似输出echo $HOME的问题
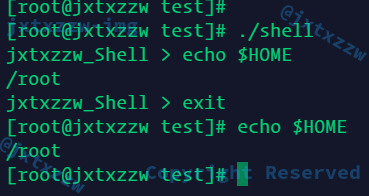
对于$HOME.txt$一类的问题,是无能为力的

试图找一个HOME.txt的环境变量肯定找不到,我的选择是让他抛出异常
Bash的做法是不管——不报错,但是也什么都没
事实上,遇到这种问题,也只能强制要求输入时候是${HOME}$
不加边界界定符,恐怕Bash也无能为力
只能随缘,看怎么解析顺眼就怎么解析了
所以我还是直接报错吧
至于双引号的问题,我看阳神代码好像没有做特别的处理
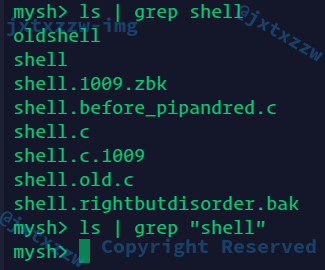
嗯,阳神果然没做这个功能
但是如果这样去做
grep "hello"
那么会把"当做参数的一部分,会去匹配"hello"而不是hello
所以我还是做一下
但是会做的比较粗糙
毕竟不是编译原理、不是写解析器
具体操作就是,当取出的一个字符串是以"开头的,就复制后面所有的内容,以及所有的空格,直到遇到第二个"
然后做空循环的strtok(),什么都不做,直到取出某个字符串的最后一个字符是"
因为目录和文件名中带空格是强烈不建议的
所以我也就不自找麻烦的去做文件重定向那里部分的这个功能了
我只做argv解析时候的这个功能
毕竟这个是会影响到命令的执行的,而文件名大不了换一个名字罢了
但是这个方法操作起来也是有问题的
因为我是strtok()取出来的,我不知道原来的字符串下标,没法一个个复制
所以我采取了曲线救国的方法
我在format的时候,就看,如果是在两个双引号中间的,我就把空格替换成不可见字符,例如
0001 1010 32 26 1A SUB (substitute) 代替
然后在envReplace()完成替回
例如正常的Bash做的是这样的
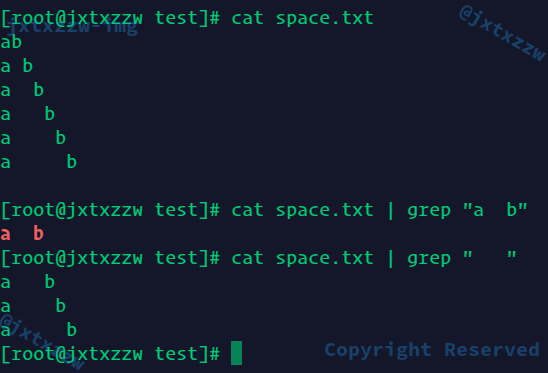
然而我的Shell


修改
if (buf[j]!='>' && buf[j]!='<' && buf[j]!='|'){
// 不是重定向符、不是管道,照抄
if (buf[j]=='"'){
inDQM = !inDQM; // 遇到双引号,这个标记反转,然后不复制字符,往后遍历
j++;
} else {
if (buf[j]==' ' && inDQM){
// 只有在双引号里面的空格需要替换
formated_buf[i] = (char)(25);
i++;
j++;
}else{
formated_buf[i++] = buf[j++]; // 其他情况都是直接抄
}
}
}
<code class="c">char* envReplace(char* str){
char* ret;
if (str == NULL){
return NULL;
} else if (str[0]=='
<img src="https://dl.jxtxzzw.com/dl/attach/1539094699961.png" alt="1539094699961" />
支持带引号了
<img src="https://dl.jxtxzzw.com/dl/attach/1539094757291.png" alt="1539094757291" />
所有带空格的也都正常了
既然空格都做了,顺手把注释符号也写了吧
要忽略<code>#</code>后面的所有内容 但是要执行这个之前的命令</code>
if (!inDQM && buf[j]=='#') {
formated_buf[i]= '\0';
break;
}

这些都搞定了,就不怕了呀
ybwu的测试数据就显得有点弱了
检查管道


完全正确
最后还有一些技巧
例如是不是在Shell显示当前路径?
对于普通用户,和root用户,按照惯例,用$和#予以区分?
这些都好做
在showPrompt()之前加一个getPrompt()函数
获取环境变量,然后调用getuid()等,都可以做到
加上去,稍微好看点
char hostName[MAX_LEN];
char pathsInfo[MAX_LEN];
struct passwd* pwd = getpwuid (getuid());
getcwd (pathsInfo, MAX_LEN);
if (gethostname(hostName, MAX_LEN))
strcpy(hostName, "unknown");
if (strlen(pathsInfo) < strlen(pwd->pw_dir) || strncmp(pathsInfo, pwd->pw_dir, strlen(pwd->pw_dir)))
sprintf(prompt, "[jxtxzzw-Shell]@%s:%s:", hostName, pathsInfo);
else
sprintf(prompt, "[jxtxzzw-Shell]@%s:~%s:", hostName ,pathsInfo+strlen(pwd->pw_dir));
switch (getuid())
{
case 0:
sprintf(prompt+strlen(prompt), "#");
break;
default:
sprintf(prompt+strlen(prompt), "$");
break;
}
但是ybwu说要自动化测试
比对输出内容?
那就不能了
全部改成mysh
老老实实什么多余的东西都不要有
然后优化代码风格
消除魔术数
做好封装
消除代码复制
代码约 $390$ 行,附于文末
写一个makefile,提交
格式是
目标:[空格]源文件 [TAB]命令
即
mysh: mysh.c
gcc mysh.c -o mysh
这个文件叫makefile
然后Bash运行make
最后,ybwu的数据实在是太弱了
送一份强一点的数据
./mysh jxtxzzw.dat
能全部跑出来,基本上就没问题了
附完整代码下载
下载提示
附测试数据下载
下载提示
2018-10-21 更新说明:
1. 增加了更多异常发生时会输出错误信息
2. 修复了部分情况下(例如,输入非法命令以后紧接着exit)不能退出的情况2018-10-25 更新说明:
1. Batcher Mode 不会输出 mysh>(突然发现作业要求说,批处理模式不输出Prompt)
2. 但是仍然会先复读一遍命令再执行(作业说,你仍需要先把输入的命令打印出来)2018-10-26 更新说明:
1. 有人说fgets不安全,会有几率复读不存在的命令后面的正常命令执行2遍
1.1 例如hhh; ls; pwd,就会先报错hhh,然后ls和pwd各自执行两遍
1.2 我在自己的服务器上(Centos 7.3 64位)没有发现这个问题,一切正常
1.3 可甩锅给不同的系统环境
1.4 如果出现这个问题,换成尝试换成read
1.5 我给出的答复是,不予解决
2. 继续优化作业没有要求的部分,例如,支持引号、支持注释(#),支持更多的管道类型……(虽然ybwu好像说,你有空最好全部实现了,越像Bash越好,但是再好也不给你加分……)
作者介绍的好清楚,我现在在写pipe,我用了processbuilder写的,结果test发现它是运行的脚本文件。。
if (chdir(cmd->argv[1]) == -1) { // perror("Change Directory Error."); write(STDERR_FILENO, error_message, strlen(error_message)); fflush(stdout); return; }代码122行
cd出错了直接return了这里命令是在子进程里执行的,出错后个人认为应该
exit,否则这里出错后会出现exit不掉的情况,因为子进程没有退出变成了一个新的进程这里应该是更改不一致的问题,我看到你后面
execvp出错了会直接exit@1多谢。
你说的很对。
这里可能是文章后期校稿不仔细造成的,因为我有修复过非法命令后
exit无效这个问题(见文末“2018-10-21 更新说明”),可能在那之后并没有更新文章和代码……@1
yes i know
非法命令后输入exit啥反应都没的bug终于有救了 tttttttttttql
SUB的ASCII码是26,代码里错写成25了,文章里写的没错
this is my comment to download
tql
tql
buck