

下载完整文章:
此区域的内容需评论后可见
旅行商问题的近似最优解(局部搜索、模拟退火、遗传算法)
关键字:旅行商问题,TSP,局部搜索,模拟退火,遗传算法
TSP问题(Traveling Salesman Problem)是一个组合优化问题。该问题可以被证明具有NPC计算复杂性。
迄今为止,这类问题中没有一个找到有效算法。
也就是说,没有一个算法能够在多项式时间内解得TSP问题的最优解,所以只能通过我们介绍的方法,即遗传算法、模拟退火算法、局部搜索,来寻求近似最优解。
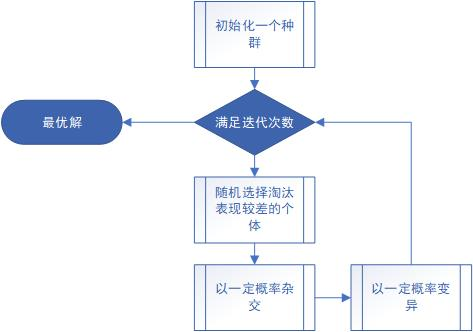
遗传算法
遗传算法(Genetic Algorithm, GA)起源于对生物系统所进行的计算机模拟研究。
它是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。
其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。
private double fitness; // 适应度
private double selectedRate; // 被选中的概率,归一化处理
@Override
public int compareTo(Species o) {
if (getRouteLength() < o.getRouteLength()) {
return -1;
} else if (getRouteLength() == o.getRouteLength()) {
return 0;
} else {
return 1;
}
}
对个体的操作有可能会影响到适应度,所以在关键操作之前必须更新适应度。
由于距离越短,表现越好,那么适应度就越高,所以可以定义适应度为距离的倒数。
/**
* 获得适应度
* @return 适应度
*/
public double getFitness() {
updateFiness(); // 返回之前必须先更新(如果需要)
return fitness;
}
/**
* 计算并设置适应度
*/
private void calculateAndSetFitness() {
updateLength(); // 计算适应度之前必须更新长度
this.fitness = 1.0 / getRouteLength();
}
后面用到轮盘赌,被选中的概率必须归一化处理。
/**
* 设置被选中的概率,归一化处理
* @param selectedRate 被选择的概率,归一化处理
*/
public void setSelectedRate(double selectedRate) {
this.selectedRate = selectedRate;
}
后面用到变异,设计到一个逆转给定区间,即1-2-3-4,逆转2-3,就变成1-3-2-4。为方便起见,封装成了一个方法。
/**
* 逆转给定区间
* @param left 左端点(包含)
* @param right 右端点(包含)
*/
public void reverse(int left, int right) {
// 逆转
while (left < right) {
City c = routeList.get(left);
routeList.set(left, routeList.get(right));
routeList.set(right, c);
++left;
--right;
}
杂交和变异都是以一定概率进行的,下面省略随机数生成和比较的部分,只给出核心代码,完整代码参见第4部分。
随机选择一对父母,随机选择一段基因。
直接把这一段父亲的基因复制到孩子对应的部分,孩子缺少的基因从母亲那里拿,已经重复的基因跳过。
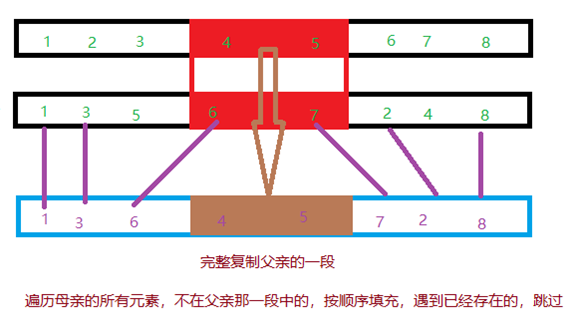
那么可以得到核心部分的代码。
// 直接把这一段父亲的基因复制到孩子对应的部分
for (int i = beginIndex; i < endIndex; ++i)
list.set(i, father.get(i));
// 孩子缺少的基因从母亲那里拿
int i = 0;
// 从头开始遍历母亲的基因
for (int j = 0; j < size; ++j) {
if (i == beginIndex)
i = endIndex; // 跳过父亲那一段
City c = mother.get(j); // 获取母亲的基因
// 如果母亲的基因已经在孩子身上,就跳过,否则加入
if (!list.contains(c)) {
list.set(i, c);
i++;
}
}
在实现的过程中,需要保证父母不是同一个个体,需要保证随机一段的序列左端点小于右端点……
得到了孩子的序列以后,构造一个对象,加入到种群中。
变异对每一个个体都有概率,以一定的概率变异
这里的处理有很多种方法,例如,随机交换任意两个城市的位置,又如,随机逆序一段路径,再如,随机选择若干个奇数位的城市重新随机打乱以后按顺序放回……
这里采用了随机逆序一段路径的方法。
事实上,也仅对收尾2个城市(4段路径)影响较大。
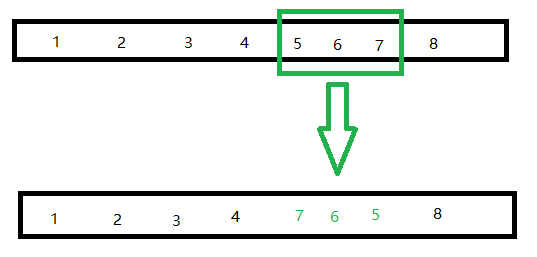
同样,可以得到核心代码。
// 随机选择一段基因,逆序
int left = (int) (Math.random() * sp.size());
int right = (int) (Math.random() * sp.size());
if (left > right) {
int tmp = left;
left = right;
right = tmp;
}
sp.reverse(left, right);
物竞天择,适者生存。
所有表现不好的个体都应该被淘汰。
考虑到表现越好,意味着路径长度越短,那么容易想到的是,把种群中所有的个体拿出来看看,按照路径长度排个序,取最短的若干名,其他淘汰。
由于个体Species已经实现了Comparable接口,所以直接放进优先级队列PriorityQueue,然后一个个取出来,要么取到取完,要么取到种群最大容量。
// 直接把个体丢掉优先级队列中,由于个体实现了Comparable接口,所以距离短的方案表现好,优先级高
PriorityQueue<Species> pq = new PriorityQueue<Species>();
pq.addAll(group);
// 清空种群,然后按照个体的表现从好到差放到种群中
group.clear();
while (!pq.isEmpty()) { // 要么放完
group.add(pq.poll());
if (group.size() == capacity) // 要么超过了最大容量就不放了
break;
为方便起见,我采用的是这样的方法,并且实践证明效果能够接受。
其主要思想是,表现越好的个体越有可能活着(当然也可能会被淘汰,只是概率太低了以至于可以认为小概率事件不发生),而表现差的个体存活的可能性就小,极有可能被淘汰(当然也可能活着)。
具体的做法是,随机选择一个概率,然后看是不是满足这个个体被选中的概率,如果是,那么就把这个个体放入到新的种群中,如果不是,就用归一化的概率减去随机概率,用新的概率检查下一个个体。
所有个体检查完,如果仍没有放满种群容量,就再次循环,再比较每一个个体,于是,表现较好的个体就可能会被放入新种群2次、3次甚至更多次,直到种群容量满了。
事实上,更常见的做法是轮盘赌。
下面给出核心部分代码。
double rate = Math.random() / 100.0;
Species oldPoint = origin.get(i);
while (oldPoint != null && !oldPoint.equals(best))
{
if (rate <= oldPoint.getSelectedRate()) {
group.add(oldPoint);
break;
} else {
rate = rate - oldPoint.getSelectedRate();
}
}
这样有可能会走到两个极端。
第一个极端,很有可能表现最好的个体被淘汰了。
尽管表现最好的个体存活的概率非常非常大,但是如果不幸发生小概率事件,把表现最好的个体淘汰了,那么就会丢失最优解。
当循环次数足够多的时候,原来的表现第二的个体会在若干次的杂交和变异中变得越来越好,并进一步优于原来表现最好的个体。
但是这样明显会使程序工作效率下降,并且,很可能若干次以后表现最好的个体再次被淘汰。
我们希望的是,表现最好的那一个,或者那两个,以1的概率一定存活。
第二个极端,表现最好的个体存活概率很大,后面的个体大多数都被淘汰了,那么整个新种群就可能会出现90%甚至更多的都是来自最好的那一个或者那两个个体,后面10%是第三、第五、第十表现好的个体。
这样就会导致其实很多时候父亲和母亲都是一样的,或者说,就是自交而不是杂交,会明显地降低效率。
综合上面这两个极端,可以给出一种妥协的方案——表现最好的个体以1的概率一定存活,但是,最多不能超过新种群的四分之一,剩下的部分按照标准轮盘赌的方案进行,但是当轮盘赌了若干次以后还没有填满种群,不再反复进行,而是直接用表现最差的个体补满剩下的若干个位置。
这样妥协的方案可以有效解决上面两个极端,且测试效果良好。
for (int i = 1; i <= talentNum; i++) {
group.add(best);// 复制物种至新表
if (oldPoint == null || oldPoint.equals(best))
group.add(origin.getLast());
由于从优先级队列取出的时候,每个个体只被取出一次,所以不会出现上面说的第二个极端,且由于优先级队列出队的顺序保证了表现最好的个体一定会在新种群中,所以不会出现上面说的第一个极端。
这样,在每一次迭代中,表现最优的个体只会越来越好,也就是说,最短路径的长度只可能变短,不可能边长,最坏的情况就是不变。
只不过这样其实就只是按照从好倒坏的顺序保留存活,超过种群数量的就直接认为是表现过差,被淘汰。
事实上,在测试的过程中,种群数量在200的时候,表现第200的已经足够差了,所以这个种群包含了各种情况的样本,可以认为是完备了。所以超过200的,虽然更差,但是同时也失去了意义,可以直接淘汰。
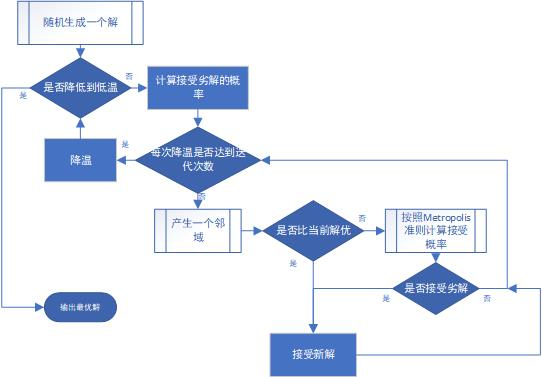
模拟退火算法
模拟退火算法(Simulated Annealing,SA)最早的思想是由N. Metropolis [1] 等人于1953年提出。
模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小。
模拟退火算法从某一较高初温出发,伴随温度参数的不断下降,结合概率突跳特性在解空间中随机寻找目标函数的全局最优解,即在局部最优解能概率性地跳出并最终趋于全局最优。
模拟退火算法是通过赋予搜索过程一种时变且最终趋于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优的串行结构的优化算法。
根据Metropolis准则,粒子在温度T时趋于平衡的概率为e(-ΔE/(kT))。
其中E为温度T时的内能,ΔE为其改变量,k为Boltzmann常数。
用固体退火模拟组合优化问题,将内能E模拟为目标函数值f,温度T演化成控制参数t,即得到解组合优化问题的模拟退火算法。
/**
* MetroPolis准则
*
* @param bestRoute
* 最优解
* @param currentRoute
* 当前解
* @param currentTemperature
* 当前温度
* @return MetroPolis准则的评估值
*/
private static double metropolis(Route bestRoute, Route currentRoute, double currentTemperature) {
double ret = Math.exp(-(currentRoute.getRouteLength() - bestRoute.getRouteLength()) / currentTemperature);
return ret;
}
当温度较高的时候,接受劣解的概率比较大,在初始高温下,几乎以100%的概率接受劣解。
随着温度的下降,接受劣解的概率逐渐减少。
直到当温度趋于0时,接受劣解的概率也同时趋于0。
这样将有利于算法从局部最优解中跳出,求得问题的全局最优解。
/**
* 能够接受劣解的概率
*
* @param currentTemperature
* 当前温度
* @return 能够接受劣解的概率
*/
private static double getProbabilityToAcceptWorseRoute(double currentTemperature) {
return (currentTemperature - ConstantValue.CHILLING_TEMPERATURE)
/ (ConstantValue.INITIAL_TEMPERATURE - ConstantValue.CHILLING_TEMPERATURE);
}
// 用shuffle随机一条路径作为初始解,并复制一份作为初始最优解
while (ConstantValue.CHILLING_TEMPERATURE < currentTemperature) {
double p = getProbabilityToAcceptWorseRoute(currentTemperature);
for (int i = 0; i < ConstantValue.SIMULATE_ANNEA_ITERATION_TIMES; i++)
// 产生邻域
if (neighbourRoute.getRouteLength() <= bestRoute.getRouteLength()) {
// 如果新解比当前解优,接受
} else if (metropolis(bestRoute, neighbourRoute, currentTemperature) > p) {
// 否则按照Metropolis准则确定接受的概率
}
}
// 按照给定的速率降温
}
局部搜索
与模拟退火方法类似,区别在于当且仅当新解比当前解更优的时候接受新解。
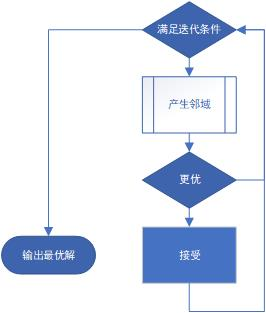
while (successfullyChanged != 0 && changed != 0) {
Route neighbour = route.generateNeighbour();
if (neighbour.getRouteLength() <= route.getRouteLength()) {
route = neighbour;
successfullyChanged--;
}
changed--;
}
算法测试
正确性测试
考虑仅有4个城市的情况。
这4个城市分别位于(1,0)、(2,0)、(1,1)、(2,1)。
显然只有2种走法,起路径长度分别为4和4.828。
三种算法都能求得正确的最优解。
遗传算法: City [index=2, x=2, y=0] -> City [index=4, x=2, y=1] -> City [index=3, x=1, y=1] -> City [index=1, x=1, y=0] -> RouteLength = 4.0 局部搜索: City [index=3, x=1, y=1] -> City [index=1, x=1, y=0] -> City [index=2, x=2, y=0] -> City [index=4, x=2, y=1] -> RouteLength = 4.0 模拟退火算法: City [index=4, x=2, y=1] -> City [index=2, x=2, y=0] -> City [index=1, x=1, y=0] -> City [index=3, x=1, y=1] -> RouteLength = 4.0
大规模数据
下面给出10个城市的运行结果。
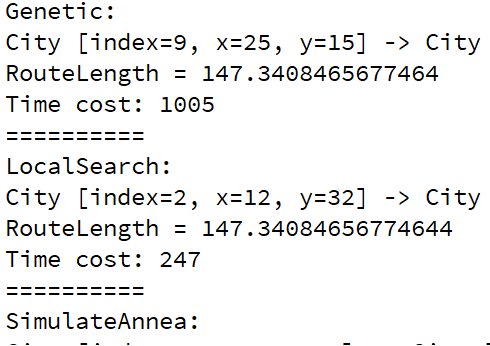
下面给出144个城市的运行结果。

算法比较
首先给出10个城市的数据。
10 1 0 0 2 12 32 3 5 25 4 8 45 5 33 17 6 25 7 7 15 15 8 15 25 9 25 15 10 41 12
这组数据的真正最优解是147.34。
下面尝试使用遗传算法运行这组数据,分别运行10次,取这10次结果的平均值和最小值。
这10次结果分别为:147.3408465677464、147.3408465677464、171.87473677989576、147.3408465677464、147.3408465677464、147.3408465677464、147.3408465677464、162.19167266106012、147.3408465677464、147.3408465677464。
这10次结果的最小值是147.34,完全命中最优解。
事实上,有80%的概率命中了最优解。
剩下的2次,一次是162,一次是171,误差较大。
但是从全局考虑,10组数据的平均值是150.9,也足够接近最优解了。
同样,使用局部搜索和模拟退火算法,对这组数据进行测试,得到了下面这张表格。
| 算法 | 10次测试最小值 | 10次测试平均值 |
|---|---|---|
| 遗传算法 | 147.34 | 150.9 |
| 模拟退火算法 | 167 | 197 |
| 局部搜索 | 147.34 | 148.9 |
从这张表中可以看到,在小数据规模的时候,模拟退火的算法准确度是最低的。
这可能是由于模拟退火是接受劣解导致的,所以在小数据规模上会出现不在最优解的可能。
下面给出更大数据规模的测试,并且下表仅列出各种算法在10次测试中出现的最小值。
| 算法 | 10次测试最小值 | 城市数与理论最优解 |
|---|---|---|
| 遗传算法 | 871 | 20个城市,最优解870 |
| 模拟退火算法 | 871 | 20个城市,最优解870 |
| 局部搜索 | 918 | 20个城市,最优解870 |
| 遗传算法 | 15414 | 31个城市,最优解14700 |
| 模拟退火算法 | 15380 | 31个城市,最优解14700 |
| 局部搜索 | 16916 | 31个城市,最优解14700 |
| 遗传算法 | 32284 | 144个城市,最优解略小于32000 |
| 模拟退火算法 | 37333 | 144个城市,最优解略小于32000 |
| 局部搜索 | 49311 | 144个城市,最优解略小于32000 |
可以看到,数据规模较大的时候,三种算法都能够比较接近最优解。
但是由于数值变大,所以绝对误差也随之增加。如果计算相对误差,可以看到相对误差仍旧处于一个很小的范围。
同时可以看到,模拟退火的准确度高于了局部搜索,局部搜索在大数据下显得误差最大,这是由于局部搜索是最原始的,难以跳出局部最优解,而模拟退火等算法能够从局部最优解中跳出。
采用与上面相同的方法,对三种算法进行测试,得到下表。
同样的,每组数据,分别对每种算法运行10次,取10次中运行时间最快的,单位为毫秒。
| 数据规模 | 算法 | 10次测试最小值(毫秒) |
|---|---|---|
| 10个城市 | 遗传算法 | 955 |
| 10个城市 | 模拟退火算法 | 995 |
| 10个城市 | 局部搜索 | 230 |
| 20个城市 | 遗传算法 | 16595 |
| 20个城市 | 模拟退火算法 | 918 |
| 20个城市 | 局部搜索 | 232 |
| 31个城市 | 遗传算法 | 2286 |
| 31个城市 | 模拟退火算法 | 1048 |
| 31个城市 | 局部搜索 | 235 |
| 144个城市 | 遗传算法 | 10080 |
| 144个城市 | 模拟退火算法 | 1441 |
| 144个城市 | 局部搜索 | 351 |
e
again
tql
tql
tql
tql
orz
orz
19196B的代码。orz%%%
评论