

Visits: 564
线程
线程的创建
#include <pthread.h> int pthread_create(pthread_t* thread, const pthread_attr_t* attr, void* (*start_routine)(void*), void* arg);
thread是一个线程的结构体,将它传递给pthread_create()来完成初始化。attr是一些必要的属性,例如设置堆栈大小、调度优先级。简单地传入NULL就可以使用默认的情况。start_routine是一个函数指针,表示了这个函数的名字,以及它的参数类型是void*,返回类型是一个void*。如果这个函数接受的是一个int参数,那么就可以写成:int pthread_create( //..., void* (*start_routine)(int), int arg);
或者,如果它返回值是一个
int,那么就可以写成:int pthread_create( //..., int (*start_routine)(void*), void* arg);
arg是传入线程开始执行的那个函数的参数,使用void*是为了可以传入任何类型的参数,以及返回任何类型的返回值。
#include <pthread.h>
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
void* mythread(void* arg) {
myarg_t *m = (myarg_t*) arg;
printf("%d %d\n", m->a, m->b);
return NULL;
}
int main(int argc, const char* argv[]){
pthread_t p;
int rc;
my_arg_t args;
args.a = 10;
args.b = 20;
rc = pthread_create(&p, NULL, mythread, &args);
//...
}
线程的结束
int pthread_join(pthread_t thread, void** value_ptr);
thread指定了要等待哪个线程执行结束。
value_ptr是指向那个希望得到的返回值的指针,由于返回值是一个void*,所以这里就是void**。
因为pthread_join()的调用会改变传入的参数的值,所以为了保留值的内容能够被带回来,需要传入的是指向这个值的指针,而不是这个值本身。
#include <stdio.h>
#include <pthread.h>
#include <assert.h>
#include <stdlib.h>
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
typedef struct __myret_t {
int x;
int y;
} myret_t;
void* mythread(void* arg){
myarg_t *m = (myarg_t*) arg;
printf("%d %d\n", m->a, m->b);
myret_t *r = Malloc(sizeof(myret_t));
r->x = 1;
r->y = 2;
return (void*) r;
}
int main(int argc, const char* argv[]){
pthread_t p;
myret_t *m;
myarg_t args = {10, 20};
Pthread_create(&p, NULL, mythread, &args);
Pthread_join(p, (void**) &m);
printf("returned %d %d\n", m->x, m->y);
free(m);
return 0;
}
需要注意的是,不要返回一个在栈中分配的指针。
例如以下写法就是有潜在风险的:
void* mythread(void* arg) {
myarg_t *m = (myarg_t*) arg;
printf("%d %d\n", m->a, m->b);
myret_t r; // ALLOCATED ON STACK: BAD!
r.x = 1;
r.y = 2;
return (void*) &r;
}
锁
int pthread_mutex_lock (pthread_mutex_t* mutex); int pthread_mutex_unlock(pthread_mutex_t* mutex);
在进入临界区之前,比如对线程加锁,直到线程离开临界区。
pthread_mutex_t lock; pthread_mutex_lock(&lock); x = x + 1; // or whatever your critical section is pthread_mutex_unlock(&lock);
锁的初始化由两种方法:
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int rc = pthread_mutex_init(&lock, NULL); assert(rc == 0); //always check success!
第二种方法是动态加锁,我们通常使用的是这种方法。
第一个参数是锁自己的地址,第二个是一组属性,可以用NULL使用默认属性。
同样地,pthread_mutex_destory()也应该被调用。
包装函数会调用同名的函数,只是可以确保不会有任何期望之外的返回值。
// Use this to keep your code clean but check for failures
// Only use if existing program is OK upon failure
void Pthread_mutex_lock(pthread_mutex_t* mutex){
int rc = pthread_mutex_lock(mutex);
assert(rc == 0);
}
另外还有两个关于加锁的函数,但是这两种方法都应该被避免。
int thread_mutex_trylock(pthread_mutex_t* mutex);
尝试加锁,如果锁已经存在,返回失败。
int thread_mutex_timedlock(pthread_mutex_t* mutex, struct timespec* abs_timeout);
在给定的时间之后返回,或者,当成功上锁以后返回,两者取先。
特别的,当timeout为 $0$ 的时候,就变成了第一种方法。
条件变量
int pthread_cond_wait(pthread_cont_t* cond, pthread_mutex_t* mutex); int pthread_cond_signal(pthread_cond_t* cond);
在pthread_cond_wait()函数中,是将调用调用的线程进行睡眠,直到有别的线程去唤醒他。唤醒的情况,通常是现在程序中有些事情发生了改变,需要正在睡眠中的线程去注意这些改变。
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
Pthread_mutex_lock(&lock);
while (ready == 0)
Pthread_cond_wait(&cond, &lock);
Pthread_mutex_unlock(&lock);
如果需要在别的线程来唤醒当前睡眠中的线程,那么就需要写:
Pthread_mutex_lock(&lock); ready = 1; Pthread_cond_signal(&cond); Pthread_mutex_unlock(&lock);
这段代码中有两件事情需要注意。
第一个是,必须确保锁是被锁上的,这样可以防止无意之间的竞态条件出现在我们的代码中(因为没有锁,语句又不是原子操作,就会导致竞态条件)。
第二个是,wait的时候除了条件变量,还给了一个锁。这是因为,当线程进入了睡眠,就会释放这个锁。因为不释放的话,别的线程就没有办法获得这个锁,然后唤醒这个线程。在唤醒之后,返回之前,pthread_cond_wait()重新获得了锁,这就保证了在整个过程最开始上锁,到最后释放锁,这个过程之间的任何一个时刻,都是持有锁的。
另外有一个比较奇怪的问题是,重新检查是在一个循环里面,而不是在一个单独的语句,这个会在后面详细说。
还有,不要用一个单个的标志来代替条件变量。
while (ready == 0)
; // spin
// 睡眠
ready = 1; // 唤醒
这一方面是由于,空循环会消耗大量的CPU周期。
另一个原因是,这有潜在的风险,容易出错,尤其是在线程之间同步的时候。
编译运行
如果需要编译一个多线程的代码,那么需要加上-pthread选项。
一些建议
- 程序简单
- 线程交互尽量少
- 初始化锁和条件变量
- 检查返回代码
- 注意传入线程和线程返回的参数
- 每一个线程都有自己的栈
- 在线程之间唤醒的时候总是使用条件变量
锁
锁机制是为了保证在多线程的程序中,有些语句能够作为原子操作被执行。
锁的基本思想
考虑最基本的一个情况:
balance = balance + 1
如果要对这个语句加锁,那么就需要写成:
lock_t mutex; // some globally-allocated lock 'mutex' ... lock(&mutex); balance = balance + 1; unlock(&mutex);
锁就是一个变量,在需要进行原子操作的语句之前,加锁,在语句执行结束之后,释放锁。
当一个线程持有锁的时候,他就能进入临界区,然后进行操作,等他操作结束,出临界区,再释放锁。
当一个线程在临界区的时候,其他线程尝试上锁进入临界区就会失败。那就会等待。
当一个线程退出临界区释放锁的时候,锁将再一次可用,此时,等待中的线程就会(最终)注意到(或者被别的线程唤醒而注意到)锁再次可用,于是在下一次尝试上锁的时候成功获得锁,然后进入临界区。
Pthread 锁
互斥访问。
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; Pthread_mutex_lock(&lock); // wrapper for pthread_mutex_lock() balance = balance + 1; Pthread_mutex_unlock(&lock);
上面的代码中只使用了一个锁变量。
通常我们会使用不同的锁来保护不同的变量,这样可以增加并发性。
- 一种粗粒度的做法是,使用一个大的锁来应对所有的不同的临界区的访问。
- 一种细粒度的做法是,不同的数据和数据结构各自都有各自的锁来保护,这样可以增加并发性,使得不同的线程可以同时访问不同的临界区。
构造一个锁
锁的关键,是要提供对临界资源的互斥访问。
为了构造一个锁,我们需要硬件的支持,以及操作系统的支持。
评估一个锁
- 首先,要看锁是不是提供了互斥访问。
- 其次,锁是不是公平的。
- 也就是说,是不是所有渴望得到锁的线程都有平等的机会来获得锁,有没有可能锁只在某个或者某几个线程之间来回切换使得一部分线程永远处于饥饿的状态。
- 最后,性能也是重要的评估指标。
控制中断
最早的解决方案是屏蔽中断。
当需要进入临界区的时候,操作系统或者硬件屏蔽中断。
void lock(){
DisableInterrupts();
}
void unlock(){
EnableInterrupts();
}
假设我们现在的程序是运行在一个单核处理器上,这样的屏蔽中断(使用了一些特别的硬件指令),然后进入临界区,是可以使得线程在访问临界资源的时候不会被打断,这样他的操作就是原子操作了。
当操作结束的时候,重新打开中断,之后就恢复正常的操作了。
这么做的最大好处就是简单。
根本不需要去关心实现的细节,只要交给操作系统去关中断就好了。
但是带来的问题却非常多。
首先,这需要对程序的极度信任。
如果一个程序能够在执行过程中关系统中断,那么说明他已经有了非常高的特权等级,我们需要极度信任这个程序才能保证这样的特权不会被滥用。
如果一个自私的线程,在一开始就关掉中断,然后独享整个CPU资源,直到自己的操作被执行完,这样对其他的线程显然是不公平的。
更坏的情况是,关中断的线程进入了死循环,由于已经屏蔽了中断,所以没有别的手段可以从中中断,只能重启系统。
其次,关中断并不能解决多核处理器的问题。
如果多个线程每个都在各自的CPU上运行,那么,无论中断是不是被屏蔽,不同核上的线程仍旧可以进入临界区,然后开始操作。
第三,关中断可能会导致有些重要的中断被丢失。例如,在关中断的情况下,CPU忽略了一个磁盘已经完成了读请求这个中断信号,那么,操作系统就永远不可能会知道什么时候要去唤醒一个等着读的线程。
最后一个潜在的问题是,现代CPU在执行关中断和重开中断的效率,比起正常的指令来说,要慢很多。
基于上面这些原因,关中断只在操作系统需要对他自己的数据结构进行原子操作的时候,或者,在他处理一大堆被触发的中断处理请求的时候才会被使用。
一个失败的尝试:只使用装载/存储
我们先用一个尝试,来看看构造一个锁需要哪些思路,并且希望能够看到为什么使用单一的变量来装载和存储并不能完成锁。
typedef struct __lock_t { int flag; } lock_t;
void init(lock_t * mutex) {
// 0 -> lock is avaliable, 1 -> held
mutex->flag = 0;
}
void lock(lock_t* mutex) {
while (mutex->flag == 1) // TEST the flag
; // spin-wait (do nothing)
mutex->flag = 1; //now SET it
}
void unlock(lock_t* mutex) {
mutex->flag = 0;
}
这段代码的思路非常简单,使用一个单一的变量flag来表示是不是有线程在上锁。
第一个线程想要进入临界区的时候会调用lock(),这会测试flag是不是为1,如果不是,那么就设置flag为1表示这个线程现在持有了锁。
当这个线程完成了临界区的操作,会调用unlock(),然后清除flag,表示不再持有锁。
如果当第一个线程已经在临界区的时候,此时,如果另一个线程也正巧调用了lock(),那么由于检测到的flag为1,就会在一个无限循环中持续自旋,等待之前那个线程调用unlock()去清除flag标记。
一旦第一个线程执行完毕,那么自选中的这个线程就会跳出无限循环,重新标记flag,然后进去临界区。
不幸的是,这有两个问题。
首先是正确性。
如果一开始flag是0,然后出现了下图的情况。

如果两个线程非常及时地同时判断了flag,那么很有可能会同时进入临界区,因为两个线程都会把flag设置为1。
另一个问题是性能。这个会在后面来慢慢解释。主要的原因是,另一个线程检查flag的过程(技术上被称为自旋),自旋等待非常消耗处理器资源,因为当一个线程获得CPU时间片的时候,他执行的只是反复检查、无限循环。
使用 Test-And-Set 来构造一个自旋锁
由于关中断并不起作用,简单的装载存储方法也不起作用。
最简单的方法是一种叫做“测试并设置”的指令,也被称作“原子交换”。
int TestAndSet(int * old_ptr, int new){
int old = *old_ptr; // fetch old value at old_ptr
*old_ptr = new; // store 'new' into old_ptr
return old; // return the old value
}
这个函数返回的是ptr指向的旧的值,并与此同时,修改这个值为新的值。
这个操作是原子操作。
当这个函数返回的时候,外层的指令就可以有足够的信息来实现一个简单的自旋锁。
假设一个线程首先调用了lock(),此时没有别的线程持有锁,所以flag是0。
当这个线程执行TestAndSet(flag, 1)的时候,这个函数会返回flag=0。
同时,调用这个函数的线程测试flag的值,发现不需要自旋,于是就可以获得锁,线程就会原子地将flag设置为1,表示自己持有锁。
当线程完成了自己在临界区的操作以后,会调用unlock(),重新将flag设置为0。
如果有另一个线程调用lock(),此时如果刚才那个线程还在持有锁,即flag=1,那么当他调用TestAndSet(flag, 1)的时候,会返回flag的旧值,也就是1。
并与此同时,这个线程也把flag设置为1。
只要原来那个线程还是持有锁的,那么这个线程就会在不断的循环中测试flag的值并始终发现值是1,这样就会不断地自旋,直到原来那个线程把锁释放了。
当别的线程把flag设置为0以后,这个线程在下一次调用TestAndSet()的时候,就会得到0的返回值,然后原子地将flag设置为1,并持有锁,进入临界区。
通过测试并设置这两个操作,我们保证了只有一个线程可以获得锁、进入临界区。
由此,这样的锁被称作是自旋锁。只是简单地自旋、等到CPU时间,直到锁再次变得可用。
在单核CPU上,自旋锁正常工作,他需要一个精准的调度算法,以保证所有的线程都有可能从自旋中出来,否则,如果没有这样一个精准的调度算法,那么很可能,线程A永远在自旋,而锁始终在线程B和线程C之间来回释放和持有。
int flag[2];
int turn;
void init(){
flag[0] = flag[1] = 0; // 1 -> thread wants to grab lock
turn = 0; // whose turn (thread 0 or 1)
}
void lock() {
flag[self] = 1; // self: threadID of caller
turn = 1 - self; // make it other thread's turn
while ((flag[1-self] == 1) && (turn == 1 - self))
; // spin-wait
}
void unlock() {
flag[self] = 0; // simply undo your intent
}
评估一个自旋锁
首先检查自旋锁的正确性。
如上文,自旋锁保证了每次只有一个线程能够进入临界区,所以是正确的。
下一个问题是公平性。
不幸的是,自旋锁并不保证公平。
在某些情况下面,一个线程有可能永远自旋下去。
只靠自旋锁是没有办法解决这个问题的。
最后一个问题是性能。
性能的分析分单核CPU和多CPU,这里从略。
Compare-And-Swap
另一种方法,被称为“比较和交换”。
基本的思想是比较ptr表示的值是不是与期望的值一致,如果一致,那么就设置ptr的值为新的值,否则就什么都不做。
int CompareAndSwap(int* ptr, int expected, int new) {
int actual = *ptr;
if (actual == expected)
*ptr = new;
return actual;
}
有了这个函数,我们可以用类似“测试并设置”的方法写出加锁的代码。
void lock(lock_t * lock){
while (CompareAndSwap(&lock->flag, 0, 1) == 1)
; //spin
}
剩下的代码和“测试并设置”是类似的。
他们工作原理也是类似的。就是检查flag是否为0,来决定是原子地设置为1并获得锁,或者是自旋等待。
char CompareAndSwap(int* ptr, int old, int new){
unsigned char ret;
// Note that sete sets a 'byte' not the word
__asm__ __volatile__ (
" lock\n"
" cmpxchg1 %2,%1\n"
" sete %0\n"
: "=q" (ret), "=m" (*ptr)
: "r" (new), "m" (*ptr), "a" (old)
: "memory");
return ret;
}
这个方法比“测试并设置”方法有更强大的功能,例如我们可以用来构造一些不需要锁机制的同步机制。
链接加载和条件存储
int LoadLinked(int* ptr){
return *ptr;
}
int StoreConditional(int* ptr, int value){
if (no one has updated *ptr since the LoadLinked to this address) {
*ptr = value;
return 1; // success!
} else {
return 0; // failed to update
}
}
LoadLinked()与普通的装载指令没有什么不同,就是把内存中的值装载到寄存器中。
关键的区别在于StoreConditional(),这个函数只在以下情况下成功(更新内存中的值):没有其他的操作对改这个内存中的值进行修改。
如果没有其他操作修改了这个内存中的值,那么会修改内存中的值为新值,并返回成功,否则返回失败而不会更新值。
用这个方法加锁的代码非常简单。
void lock(lock_t* lock) {
while (1) {
while (LoadLinked(&lock->flag) == 1)
; // spin until it's zero
if (StoreConditional(&lock->flag, 1) == 1)
return; // if set-it-to-1 was a success: all done
// otherwise: try it all over again
}
}
void unlock(loct_t* lock) {
lock->flag = 0;
}
首先,一个线程简单地检查flag的值是不是为0,然后决定是不是要自旋。
如果线程能够持有锁,那么就去检查条件存储指令,若条件存储指令执行成功,那么原子地将flag的值修改为1并进入临界区。
如果有一个线程调用了lock(),执行了LoadLinked(),并返回了0,在他执行StoreConditional()将flag设置为1之前,他被中断了,切换到了另一个线程,另一个线程也执行了LoadLinked(),也获得了0并继续执行。
此时,这两个线程都执行了LoadLinked()并都试图执行StoreConditional(),但是显然,最关键的特性保证了,只会有一个线程最终成功地执行了StoreConditional(),将flag设置为1,并进入临界区,另一个线程会因为StoreConditional()执行失败而不能获得锁,那就会自旋等待、尝试再次获得锁。
更简洁的写法如下:
void lock(lock_t* lock) {
while (LoadLinked(&lock->flag) || !StoreConditional(&lock->flag, 1))
; // spin
}
Fetch-And-Add
取值并加一的指令,也是会原子地将某一个值加1。
int FetchAndAdd(int * ptr){
int old = *pyr;
*ptr = old + 1;
return old;
}
使用这个指令,可以构造一个打点计数法的锁。
与使用单一的值不同,Ticket Lock会使用两个变量分别记录当前的打点数、以及当前是轮到了谁。
typedef struct __lock_t {
int ticket;
int turn;
} lock_t;
void lock_init(lock_t* lock){
lock->ticket = 0;
lock->turn = 0;
}
void lock(lock_t* lock) {
int myturn = FetchAndAdd(&lock->ticket);
while (lock->turn != myturn)
; // spin
}
void unlock(lock_t * lock){
lock->turn = lock->turn + 1;
}
当一个线程希望得到锁的时候,他首先原子地将打点计数加1,这个打点计数的值会被作为自己的轮次,也就是什么时候轮到自己。
全局变量lock->turn表示现在轮到的是谁。
如果myturn == turn,那么说明现在轮到的就是自己,自己就可以进入临界区。
当自己结束操作的时候,退出临界区,释放锁。释放锁的操作就是简单地将轮次加1,表示自己结束了,现在轮到的是下一个人。
这个方法与上面所有方法最大的不同,在于他保证了所有线程都有机会得到执行,一旦某一个线程企图获得锁,他就会被分配打点数,那么只要他有了自己的轮次,总有一天,他之前的线程们会做完自己的事情,然后一个一个加1地把轮次往后传递,就会轮到自己。
之前所有的方法都没有做这样的保证,例如自旋锁,就可能会导致某个线程无止境地等待下去。
太多的自旋
太多的自旋会浪费大量的CPU资源。
试想,加入有100个线程,都会访问同一个临界区。
第1个线程成功获得锁,就会进去临界区。
此时CPU时间片到了,交给第2个线程,第2个线程会花整个的CPU时间去自旋、等待。
同样的事情会发生在剩下的99个CPU上。
如果每个CPU时间片是1秒,那么,每100秒钟,有99秒是在自旋、等待,浪费了大量的CPU资源。
睡眠
硬件的支持已经给了我们足够的支持来实现一个锁,甚至是一个公平的锁(使用了打点计数器的锁)。
但是我们仍然面临着一个巨大的问题:当线程不能进入临界区而开始自旋等待的时候,他只能无尽的等待下去直到持有锁的线程再次占据CPU时间?
不如,就让得不到锁的线程睡觉去吧。
我们假设操作系统已经提供了一个睡眠机制yield(),如果线程想要放弃自己的CPU时间,让别的线程来执行,那么他就可以调用这个函数。
线程可以处于运行态、就绪态和阻塞态,睡眠机制是把一个线程从运行态转变成就绪态,然后让另一个线程去执行。
考虑两个线程在一个CPU上执行的情况。在这种情况下,睡眠机制就可以工作的非常好。
如果一个线程调用了lock()并最终发现锁已经被别人持有了,那么他会睡眠,把CPU时间让出来,这样就会让持有锁的CPU继续执行完临界区的操作。
void int(){
flag = 0;
}
void lock(){
while (TestAndSet(&flag, 1) == 1){
yield(); // give up the CPU
}
}
void unlock(){
flag = 0;
}
下面我们考虑有很多线程(例如100个)反复争夺一个锁的情况。
若有一个线程持有了锁并在释放锁之前的这段时间,其余99个线程每个都会尝试调用lock(),接着就会发现锁已经被别人持有了,然后就会放弃CPU时间。
假设以一种轮盘赌的方式,99个线程每一个都会执行这个“运行-睡眠”的模式,直到这个线程能够获得锁并继续运行。
这样的话,就比之前的自旋等待的方法(会浪费99个CPU时间片去自旋)已经剩下了巨大的时间。
但是,开销仍然是巨大的,因为存在着99个CPU时间片的上下文切换,要保存现场、切换、测试发现上锁着,然后睡眠,再保存现场、恢复原来的现场……
更坏的情况是,即便如此,我们也根本没有解决饥饿问题。
一个线程可能会陷入无止境的睡眠,当其他线程之间反复地进入和退出临界区,即锁只在有限个线程之间来回持有。
我们需要一个机制,来直面这些问题了。
睡眠队列
我们之前的方法的真正问题在于他太依赖机遇了。
一个调度器需要决定哪个线程是接下来运行的。
如果这个调度器做了一个错误的决定,那么,运行的线程要么自旋等待,要么立刻睡眠、放弃CPU时间。
不管是哪一种方法,都潜在地浪费了时间,而且没有解决饥饿。
因此,我们必须要弄出一种控制机制,来发掘到底哪个线程会在当前线程释放锁之后获得锁。
要做到这件事,光靠硬件的支持已经不够了,要操作系统的支持了。
我们需要操作系统有一个队列来保持追踪哪些线程在等待锁。
为了简化问题,我们会使用Solaris提供的支持,即park()来让调用的线程进入睡眠,以及unpack(threadID)来把一个由threadID指定的线程唤醒。
这两个方法可以用来构造一个锁,使得一个线程尝试上锁却发现锁已经被别人持有的时候会睡眠,同时,当锁再次可用的时候,会被唤醒。
typedef struct __lock_t {
int flag;
int guard;
queue_t *q;
} lock_t;
void lock_init(lock_t* lock){
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(loct_t* m) {
while (TestAndSet(&m->guard, 1) == 1)
; // acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park();
}
}
void unlock(){
while (TestAndSet(&m->guard, 1) == 1)
; // acquired guard lock by spinning
if (queue_empty(m->q))
m->flag = 0; // let go of lock; no one wants it
else
unpark(queue_remove(m->q)); // hold lock (for next thread!)
m->guard = 0;
}
在这段代码中,我们用之前的Test-And_Set方法,与一个存放等待锁的线程们的队列放在一起,组成了一个更加高效的锁。
同时,我们使用睡眠队列来决定哪个线程会得到下一个上锁的机会,这就避免了饥饿。
下面要说说守卫guard的使用。
守卫就是一个自旋锁,他用来保护的是对flag的操作和对睡眠队列的操作。
这样的实现方法完全没有避免自旋等待带来的浪费。
一个线程在获得或者释放锁的时候,可能会被打断,然后CPU时间片会交给下一个线程,那么,这就会导致别的线程(在守卫这里)自旋地等待之前那个线程再次运行。
然而,守卫守护着的这段自旋时间,真的是太短了,他只有关于lock和unlock的几句指令而已,而不是用户定义的临界区,因此,这短短的自旋时间可以被认为是合理的。
接着,你可能已经注意到了,在lock()里面,当一个线程不能获得锁的时候,我们只是把这个线程加入到了睡眠队列(通过调用gettid()来获得线程的ID),然后设置守卫为0,并开始睡眠。
这里需要注意的是,释放守卫必须在park()之前,不然,自己都睡着了,谁来把守卫放了。
还有一个值得注意的地方,当一个线程唤醒另一个线程的时候,并没有把flag重置为0。
当一个线程被唤醒的时候,他就像是从park()那里睡醒了,别忘了我们让他在睡觉之前释放了守卫,那么,当他还是在那里睡醒的时候,他根本就没有守卫,,所以他甚至不可能有机会把flag设置为1。
因此,我们就直接把锁从释放锁的线程直接传递给了下一个想要得到锁的线程,而不会把flag设置为0。
最后,还要提一个竞争条件。那就是在park()之前的恰恰好的时间。
如果一个线程就要睡眠了,他应该要睡到锁再次可用。
在他刚刚要执行park()的时候,恰好CPU时间片到了,换到了另一个线程,这个线程恰好是持有锁的那个线程,而且,恰好已执行完了临界区的操作。
那么,这个线程就会释放锁,然后从睡眠队列中会找到刚才这个线程。
但是别忘了,刚才那个线程刚刚准备睡觉,就被打断了,所以,当CPU时间片再次轮转到他的时候,他就会睡觉了,然后就真的去park()了,在这种非常巧合的情况下,刚要睡觉的线程,很可能就会永远睡下去。这种问题有时候被叫做唤醒等待竞争。
Solaris为了解决这个问题引入了一个新的函数setpark()。
当执行这个函数的时候,一个线程可以声明他将要睡觉。
在他刚要准备睡觉而其实没有睡的时候,如果非常巧合的,发生了时间片轮转,然后,另一个线程调用了unpark(),那么,这个即将准备park()的线程就立刻返回,而不是开始睡觉。
只需要做非常小的改动。
queue_add(m->q, gettid()); setpark(); // new code m->guard = 0;
一个不同的解决方案,可以将守卫传递进内核,在这种情况下,内核可以原子地进行上锁和出队。
这东西挺绕的,我再来理一理。
我自己是这样理解的。
有一个房间,房间门口有一个守卫,房间里面有一个临界区和若干个椅子。
首先,我要用TestAndSet来确认守卫是空的。
守卫是空的话,我就获得守卫,然后进去房间,做后面的事情。
如果守卫正忙,那么我就需要自旋地等待守卫空闲。
由于在房间里面做的事情只是有限个语句而不是整个临界区,所以自旋等待的时间会非常短。
但进入房间以后,我要看我是上锁还是释放锁。
先说上锁。
现在我已经进入到房间里面了,我想要到临界区去做事情。
我去看看锁是不是可用,如果锁可以用,那么我就把锁拿上(设置flag=1),然后进去临界区,做我做的事情。
在我进入临界区之前,我释放守卫(guard=0),让守卫可以回到门口做别的事情。
如果锁不可用,那么,就说明有人持有锁了。
这个时候就我要看一下自己的ID,把自己信息登记在睡眠队列中,就相当于记在一张纸上,然后在房间里面找个座位坐下睡觉。
在我睡觉之前,我要在纸上记录下我的信息,然后告诉守卫,你被释放了,可以回去了。
再说释放锁。
我从临界区回来,并且我通过守卫进入了房间。
因为我从临界区回来了,现在手上拿着锁,我先去桌子上看看那张纸,看看下一个记录着的人是谁,然后把他唤醒,然后把我手上的锁传递给他,意思是,我的事情做完了,下一个是你,你可以拿着我的锁去临界区了。然后,这个人就持有了锁,锁从我传递给了他,中间我并没有把锁放下。
我在桌上看到的纸是空白的,没有在睡觉的人,所有的椅子都是空的,那么我就把锁放下flag=0,走人。
不同的操作系统
不同的操作系统对线程和锁有不同的支持。
从略。
二相锁
Linux系统中有一种实现锁的旧方法,被称为二相锁。
void mutex_lock (int *mutex) {
int v;
/* Bit 31 was clear, we got the mutex (this is the fastpath) */
if (atomic_bit_test_set (mutex, 31) == 0)
return;
atomic_increment (mutex);
while (1) {
if (atomic_bit_test_set (mutex, 31) == 0) {
atomic_decrement (mutex);
return;
}
/* We have to wait now. First make sure the futex value
we are monitoring is truly negative (i.e. locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait (mutex, v);
}
}
void mutex_unlock (int *mutex) {
/* Adding 0x80000000 to the counter results in 0 if and only if
there are not other interested threads */
if (atomic_add_zero (mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex,
wake one of them up. */
futex_wake (mutex);
}
从略。
基于锁的并发数据结构
如何在某些数据结构中加入锁,使得这个数据结构是线程安全的,同时有较好的性能,能够被多个线程并发地执行。
并发计数器
最简单的是计数器。
typedef struct __counter_t {
int value;
} count_t;
void init(counter_t* c){
c->value = 0;
}
void increment(counter_t* c){
c->value++;
}
void decrement(counter_t* c){
c->value--;
}
int get(counter_t* c){
return c->value;
}
现在要在这个数据结构中加锁,使得他是线程安全的。
typedef struct __counter_t {
int value;
pthread_mutex_t lock;
} count_t;
void init(counter_t* c){
c->value = 0;
Pthread_mutex_init(&c->lock, NULL);
}
void increment(counter_t* c){
Pthread_mutex_lock(&c->lock);
c->value++;
Pthread_mutex_unlock(&c->lock);
}
void decrement(counter_t* c){
Pthread_mutex_lock(&c->lock);
c->value--;
Pthread_mutex_unlock(&c->lock);
}
int get(counter_t* c){
Pthread_mutex_lock(&c->lock);
int rc = c->value;
Pthread_mutex_unlock(&c->lock);
return rc;
}
这里只简单地加了一个锁,在结构体的方法被调用前,先加锁,然后等执行结束,再释放锁,就使得计数器是线程安全的了。
有点像使用 monitor 构造的数据结构,会自动在调用对象的方法的时候自动加锁和释放锁。
在做了这个修改以后,如果并发的程序运行效率低,就需要优化,否则,如果运行效率已经很好了,就完工了,没有必要做更多的事情。
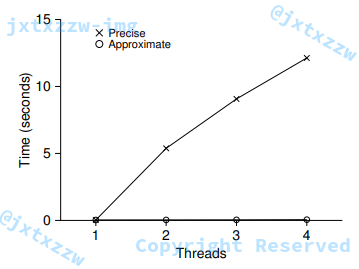
如图所示的情况,使用一个线程花的时间非常少,用的线程越多,反而效率大幅度下降。
理想的情况是,所有的线程是并行地处理事情的,所以多个线程应该并不比一个线程花更多的时间。
一种优化的方法是,采用一个全局的计数器,以及每一个线程(例如每一个CPU核上)有一个局部的计数器。
每一个CPU上的局部的计数器,配备一个局部的锁,一个全局的计数器,配备一个全局的锁。
这是基于这样的假设,每一个核也许又不止一个线程,所以需要加锁,如果每一个核只有一个线程,那么就不需要局部的锁了。
具体的操作过程,是每个核计数的时候,都只增加自己局部计数器上的值,给自己局部的计数器加1,不影响其他核的计数器,也不影响全局的计数器,每一个核上对计数器的访问,是用自己对应的锁来控制的,因此,每一个核上的局部计数器都可以同时地进行计数,而不会引起竞争。
那么如何控制全局计数器的更新呢?局部的值周期性地将自己的值加到全局计数器上,并重置自己的计数。
所谓的周期性,是取决于阈值的,当局部计数器的值达到阈值的时候,局部计数器的值就会把自己的值加到全局计数器上,然后重置自己的计数。
如果阈值被设置太小,那么情况就会退化到之前那个不具备拓展性的计数器。
如果阈值被设置太大,那么应对多核的情况就会得到大大提升,但是显然,全局计数器的值未必是最新的,而且可能会大大落后于真实值。
如果想要得到精确的全局计数器的值,最简单的方法就是每一个核依次对全局计数器上锁,然后将自己的值更新到全局计数器,依次进行,直到所有的计数器更新了自己的值。
需要注意的是,这种方法必须在一个特定的顺序下进行,以避免可能发生的死锁。
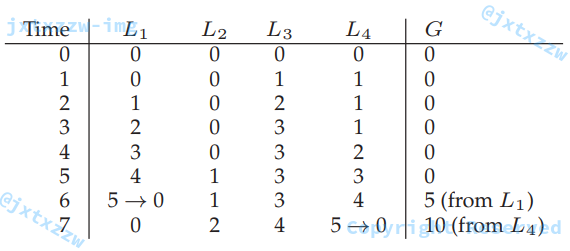
在这种情况下,性能得到了极大的提升。
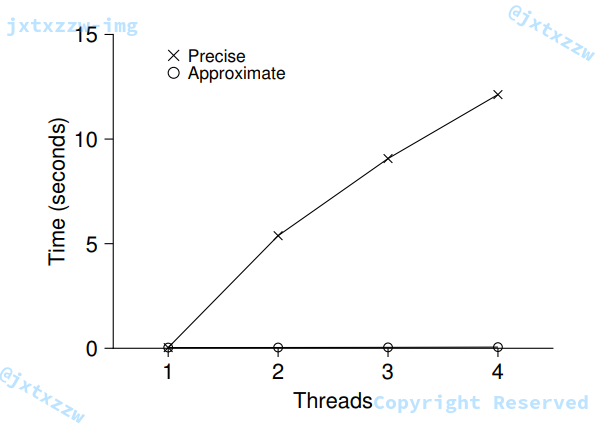
在图示的情况下,阈值被设置成了 $1024$。
当阈值太小的时候,性能会较差,但是全局计数器的值几乎永远是精确的,而阈值太大的时候,性能提升了,但是全局计数器的值会落后真实值很多。在性能和准确度之间需要找到一个妥协。
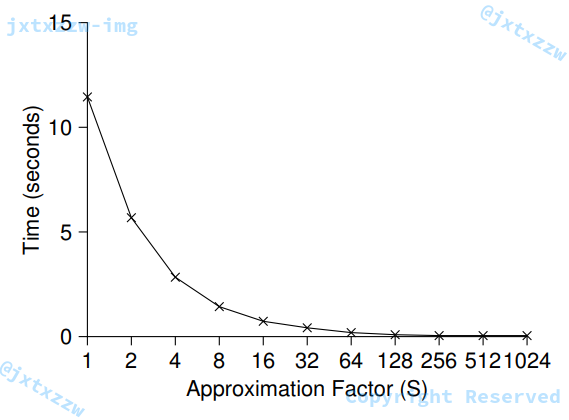
一个粗略的实现:
typedef struct __counter_t {
int global; // global count
pthread_mutex_t glock; // global lock
int local[NUMCPUS]; // local count (per cpu)
pthread_mutex_t llock[NUMCPUS]; // ... and locks
int threshold; // update frequency
} counter_t;
// init: record threshold, init locks, init values of all local counts and global count
void init(counter_t* c, int threshold) {
c->threshold = threshold;
c->global = 0;
pthread_mutex_init(&c->glock, NULL);
int i;
for (i = 0; i < NUMCPUS; i++){
c->local[i] = 0;
pthread_mutex_init(&c->llock[i], NULL);
}
}
// update: usually, just grab local lock and update local amount once local count has risen by 'threshold', grab global lock and transfer local values to it
void update(counter_t* c, int threadID, int amt){
int cpu = threadID % NUMCPUS;
pthread_mutex_lock(&c->llock[cpu]);
c->local[cpu] += amt; // assumes amt > 0
if (c->local[cpu] >= c->threshold) { // transfer to global
pthread_mutex_lock(&c->glock);
c->global += c->local[cpu];
pthread_mutex_unlock(&c->glock);
c->local[cpu] = 0;
}
pthread_mutex_unlock(&c->llock[cpu]);
}
// get:just return global amount (which my not be perfect)
int get(counter_t* c) {
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val; // only approximate
}
如果需要得到精确的值,可以强制先把所有局部计数器的值转移到全局计数器,然后返回全局计数器的值。
例如:
int getAcuracy(counter_t* c) {
for (int i = 0; i < NUMCPUS; i++){
pthread_mutex_lock(&c->llock[i]);
pthread_mutex_lock(&c->glock);
c->global += c->local[i];
pthread_mutex_unlock(&c->glock);
c->local[i] = 0;
pthread_mutex_unlock(&c->llock[i]);
}
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val;
}
并发链表
下面来测试一下更加复杂的结构,比如队列。
还是先从最简单的方法开始,忽略了一些其他的功能(查找、删除等等),而只关注于并发的插入。
// basic node structure
typedef struct __node_t {
int key;
struct __node_t* next;
} node _t;
// basic list structure (on used per list)
typedef struct __list_t {
node->t* head;
pthread_mutex_t* lock;
} list_t;
void List_IInit(list_t* L){
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
int List_Insert(list_t* L, int key) {
pthread_mutex_lock(&L->lock);
node_t* new = malloc(sizeof(node_t));
if (new == NULL){
perror("malloc");
pthread_mutex_unlock(&L->lock);
return -1; // fail
}
new->key = key;
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0;
}
int List_Lookup(list_t* L, int key){
pthread_mutex_lock(&L->lock);
node_t* curr = L->head;
while (curr){
if (curr->key == key){
pthread_mutex_unlock(&L->lock);
return 0; // success
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return -1;
}
如你所见,这个代码只是简单地在插入之前加了一个锁,然后在退出之前释放了锁。
需要注意的是,在一种非常少发生的情况下,那就是malloc()会失败的情况下,代码也仍然需要正确地释放锁,然后才能报告插入失败。
现在,又来了一个挑战。
我们能不能重写一个插入和查找的方法,使得他能够避免在malloc()失败的时候仍然需要加锁和释放。
回答是肯定的。我们只需要把加锁和释放锁,包围住真正的临界区就可以了。
事实上,查找的部分并不需要被锁住。
而malloc()本身就是线程安全的,每一个线程都可以调用它,而不需担心竞争条件或者其他并发的错误。
只有当更新链表的时候,才需要持有锁。
void List_Init(list_t* L){
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
void List_Insert(list_t *L, int key) {
// synchronization not needed
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
return;
}
new->key = key;
// just lock critical section
pthread_mutex_lock(&L->lock);
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
}
int List_Lookup(list_t *L, int key) {
int rv = -1;
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
rv = 0;
break;
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return rv; // now both success and failure
}
在查找的环节,减少了临界区包围的代码的量,同时保证了函数的出口是单一的,这样就可以避免一些潜在的危险,例如,忘记了unlock()。
尽管我们实现了链表的并发,但是并发的效果并没有随着线程的增加依然保持较高的性能。
有一种方法是被叫做 hand-over-hand locking,或者被简称为 lock coupling。
这个方法的思想非常简单,就是不再是用单一的锁来锁住整个链表,而是对链表的每个节点加一个锁。
当遍历链表的时候,每个节点首先获取下一个节点的锁,然后释放自己的锁。
注意这种方法有时候是有效的,但是有时候,不断对每一个节点加锁、解锁、加锁、解锁,开销是非常大的,还不如只对整个链表加锁。
并发队列
前面两个例子已经给出了,改造一个数据结构使得他能够并发,就是简单的加一个超大的锁。
对于队列,我们跳过了这个最简单的方法,考虑一个并发更好的队列。
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
仔细阅读代码就会发现,代码中有两个锁,一个是表头,一个是表尾,这样做的目的是让入队和出队可以并发的进行。
在一般情况下,入队只会与队尾相关,而出队只会与表头相关。
有一个技巧是增加了一个虚拟节点,而不是使用NULL,这样做的好处就是可以分离了入队和出队操作,也就是可以把对表头的锁和对表尾的锁分离开来。
队列是在多线程中经常被使用的,然而,這了只是简单的实现了并发的队列,并不适用于很多程序的需求。
一个更完善的队列,应该是会有一个边界守护,当一个线程企图对一个空队列或者满队列操作的时候后,应该要等待。
并发哈希表
#define BUCKETS (101)
typedef struct __hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
int i;
for (i = 0; i < BUCKETS; i++) {
List_Init(&H->lists[i]);
}
}
int Hash_Insert(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Insert(&H->lists[bucket], key);
}
int Hash_Lookup(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Lookup(&H->lists[bucket], key);
}
最后用一个广泛使用的并发哈希表来结束。
考虑以一种简化的,没有重新调整大小的哈希表。
这样的操作是非常简单的,就是用我们之前的并发队列来做。而且效果异常好。
原因是,锁并不是加在整个表上的,而是加在了每一个哈希桶,也就是每一个队列上。
这样就可以支持更多的并发操作。
哈希表的使用,使得性能比简单的并发链表提高了非常多。
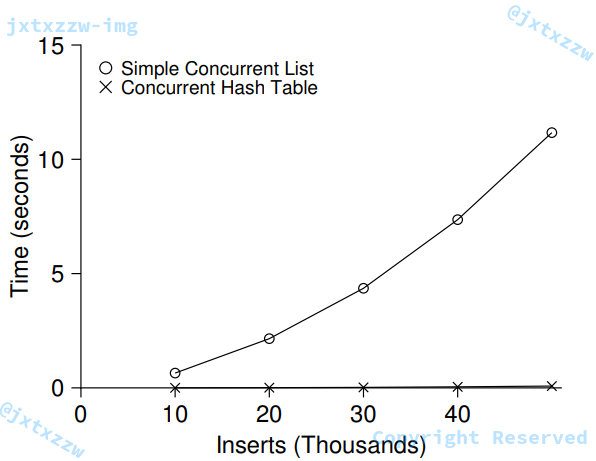
HHH